
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- cross join
- 군집화
- 태블로
- 최종 프로젝트
- streamlit
- lambda
- 전처리
- 프롬프트 엔지니어링
- 기초통계
- 머신러닝
- 히트맵
- 데이터분석
- If
- Python
- GA4
- 시각화
- 서브쿼리
- pandas
- 클러스터링
- da
- SQLD
- jd
- Chat GPT
- 기초프로젝트
- 팀프로젝트
- data analyst
- SQL
- 데이터 분석
- 프로젝트
- 크롤링
- Today
- Total
세조목
최종 프로젝트 20일차(24.04.17) 본문
최종 프로젝트 19일차입니다.
금일은 어제부터 시작된 특성 및 긍/부정 점수 검토 작업을 마무리했습니다.

어제 퇴실하기 전 팀원들과 얘기한건
이렇게 하다가는 시간이 너무 많이 소요되니
'가장 오류값이 많은 bread와 beverage 컬럼에 대한 값만 확인하자' 였습니다.
오늘 오전 9시까지 완성본을 제출하기로 약속했기때문에
새벽 4시 30분에 일어나서 일과를 시작했고,
6시 30분부터 작업을 시작했습니다.
다행히 9시까지 팀원 모두 자료를 제출해주어서 제 때 데이터를 취합할 수 있었습니다.
그렇게 해서 완성된 데이터셋을 가지고서 튜터님들께
어떤 클러스터링 모델을 사용하는 것이 좋을지에 대해 질문드렸습니다.

확인 결과 저희 데이터셋에는 K-Means++ 모델이 적합했습니다.
처음에는 저희가 가지고 있는 데이터셋의 차원(컬럼) 개수가 27개가 넘으니
코사인 거리를 활용한 K-Means 모델을 써야하지 않을까 생각했는데요,
코사인 거리 사용 유무를 판단할 때 단순히 '차원의 개수'만을 가지고서 판단하면 안 됐습니다.
각 데이터의 비정형 유무도 함께 살펴야 했습니다.
예를 들어 텍스트와 같은 비정형 데이터의 경우에는 벡터의 방향성도 함께 살펴야하기때문에
당연히 코사인 거리를 사용할 수 밖에 없습니다(코사인 거리는 방향성도 함께 고려합니다).
0. 표준화(standard scaler, min-max scaler)
1. 실루엣계수, 엘보우메소드(scree plot) 그래프 그리기
→ 실루엣계수 for 최적의 K의 개수 확인
→ scree plot for 최적의 차원(컬럼)의 개수 확인
2. 각 컬럼별 분포 그래프 그려보기
3. 모든 컬럼 사용하여 클러스터링 진행하기
4. 컬럼간 상관관계 히트맵차트로 그리기
5. 컬럼 다이어트 하기클러스터링 관련해서 저희가 이제부터 해야하는 To-Do list입니다.
EDA
우선 저희가 가지고 있는 데이터셋을 가지고서 EDA를 진행했습니다.



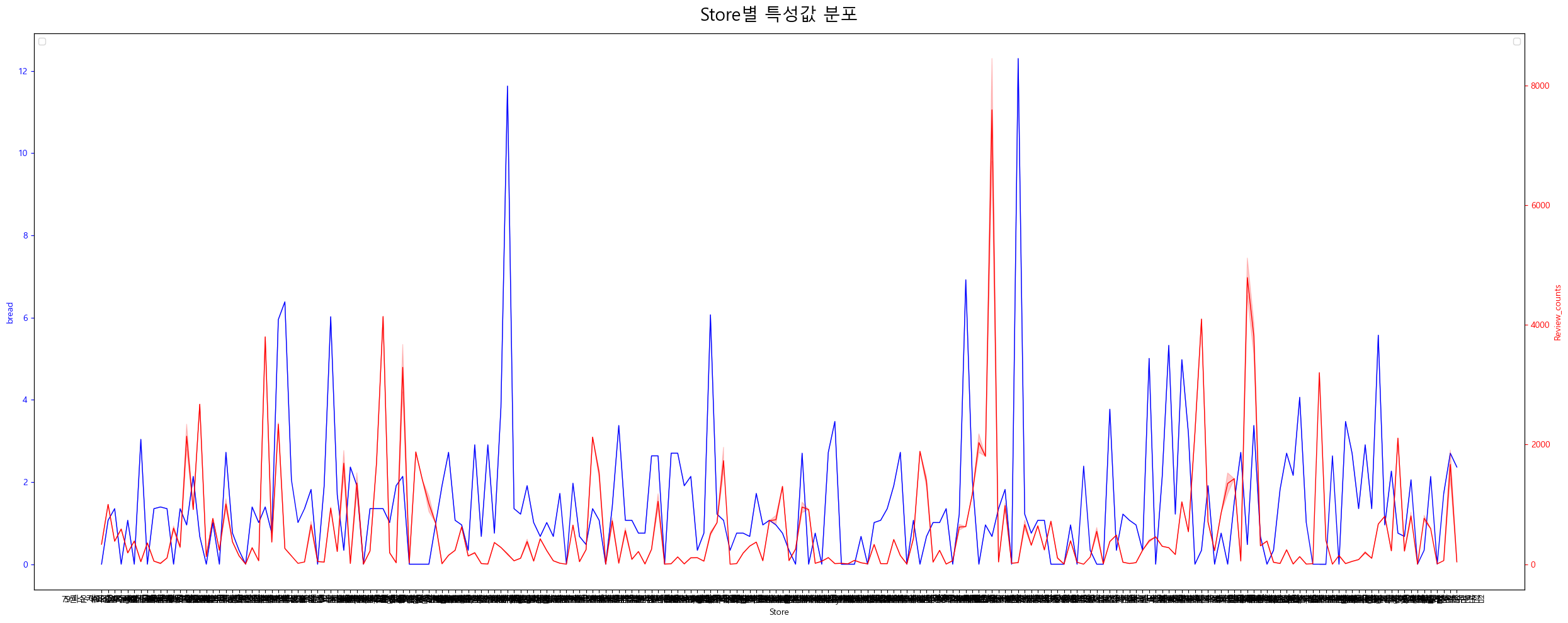



각 특성별 분포는 어떻게 되어있는지,
가게별 특성 분포는 어떻게 되어있는지,
정규분포에 가까운 분포인지,
변수들간의 상관관계는 어떤지
등등을 살펴봤습니다.
그러던 중 아래 이미지에서와 같이 값이 1인 경우가 있는 것을 확인했는데
실제 리뷰 확인 결과 1점을 부여할 필요가 없다고 판단되는 경우에는 적당한 점수로 대체했습니다.
명확한 기준을 세우지는 않았고 팀원들과 함께 리뷰를 보며 정했습니다.


그 외에 null값 처리도 함께 진행했습니다.


표준화

저희의 데이터셋은 Review 관련 컬럼과 특성 컬럼간 값의 규모 차이가 큽니다.
특성 컬럼의 경우 모두 -100에서 100사이의 값을 가지지만,
Review 관련 컬럼의 경우는 위에서 확인할 수 있는것처럼 최대 2만이 넘어가는 값도 있습니다.
그래서 표준화를 진행해주어야하는데
저희가 사용한 모델은 Standard Scaler였습니다.
EDA했을 때 이상치가 있는 것으로 확인되어서 이상치에 강건한 Robust scaler를 사용할까 싶었지만
특성 컬럼에 속하는 값들이 1분위, 3분위 수가 없기때문에 해당 모델을 사용할 수 없었습니다.
MinMax scaler도 얘기가 나오기는 했으나 표준화 했을 때 모든 값들이 0과 1 사이로 들어오는 MinMax 모델의 경우
리뷰수 최대값이 2만인 우리 데이터셋에 적용했을 때 나머지값들이 대부분 0에 수렴하여 이상치 처리에 약할 것으로 판단했기 때문입니다.
그래서 저희는 평균을 0으로, 분산을 1로 조정해주는 Standard scaler를 사용하기로 결정했습니다.
PCA, K-Means 샘플 코드 작성
내일부터 본격적으로 시작되는 클러스터링 분석에 앞서
샘플 코드를 먼저 작성했습니다.
한 명이 코드를 작성 해놓으면 다른 팀원들은 해당 코드를 가지고서
클러스터링을 돌리면 되기 때문에 훨씬 효율적이기 때문입니다.


# Scree plot
n_feature = len(df_bread_anal_mm.columns)
pca_scree = PCA(n_components=n_feature)
pca_scree.fit(df_bread_anal_mm)
pc_arr = np.arange(pca_scree.n_components_)+1
vals = pca_scree.explained_variance_ratio_
cumvals = np.cumsum(vals)
fig, ax1 = plt.subplots(figsize=(8,6))
ax1.bar(pc_arr, vals, color = ['#00da75', '#f1c40f', '#ff6f15', '#3498db'])
ax1.set_xlabel("PC")
ax1.set_ylabel("Variance")
ax1.set_title("Scree plot")
ax2 = ax1.twinx()
ax2.plot(pc_arr, cumvals, color = '#c0392b')
ax2.set_ylabel("Cumulative Variance")
plt.show()
# 실루엣 계수
k = 21
fig, ax = plt.subplots(1,1)
kmeans = KMeans(n_clusters = k, random_state=0).fit(df_bread_anal_mm)
silhouette_vals = silhouette_samples(df_bread_anal_mm, kmeans.labels_)
y_ticks = []
y_lower = y_upper = 0
for c_num in np.unique(kmeans.labels_):
cluster_silhouette_vals = silhouette_vals[kmeans.labels_==c_num]
y_upper += len(cluster_silhouette_vals)
cluster_silhouette_vals.sort()
ax.barh(range(y_lower, y_upper), cluster_silhouette_vals, height=1)
y_lower += len(cluster_silhouette_vals)


# elbow plot
from yellowbrick.cluster.elbow import kelbow_visualizer
kelbow_visualizer(KMeans(random_state=0), df_bread_anal_ss_ver_4, k=(2,25))
# Radar plot
import plotly.graph_objects as go
def plot_radar_from_centroid(df_centroids):
df_centroids = df_centroids.drop('size', axis=1)
fig = go.Figure()
categories = df_centroids.columns
for row in df_centroids.iterrows():
fig.add_trace(go.Scatterpolar(
r=row[1].tolist(),
theta=categories,
fill='toself',
name='cluster {}'.format(row[0])
))
fig.update_layout(
autosize=False,
width=1000,
height=800,
)
fig.show()
plot_radar_from_centroid(df_centroids)수준별 학습때 학습했던 내용이라서
코드를 작성할 때는 크게 어려움 없이 작성할 수 있었습니다.
이제 내일부터는 본격적으로 클러스터링 분석 작업에 들어갑니다.
컬럼을 넣었다 뺐다 하면서 군집화가 잘 되었는지를 판단해야하기때문에
팀원들과 분량을 나눠서 진행할 것 같습니다.
'데이터 분석 공부 > 프로젝트' 카테고리의 다른 글
| 최종 프로젝트 22일차(24.04.19) (0) | 2024.04.19 |
|---|---|
| 최종 프로젝트 21일차(24.04.18) (1) | 2024.04.18 |
| 최종 프로젝트 19일차(24.04.16) (0) | 2024.04.16 |
| 최종 프로젝트 18일차(24.04.15) (0) | 2024.04.15 |
| 최종 프로젝트 17일차(24.04.12) (0) | 2024.04.12 |



