
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- If
- jd
- 시각화
- 데이터 분석
- 머신러닝
- SQLD
- 프로젝트
- Python
- SQL
- 프롬프트 엔지니어링
- 태블로
- GA4
- 기초프로젝트
- 서브쿼리
- lambda
- da
- 군집화
- 클러스터링
- streamlit
- cross join
- 크롤링
- pandas
- 데이터분석
- Chat GPT
- 히트맵
- 전처리
- 기초통계
- 팀프로젝트
- data analyst
- 최종 프로젝트
- Today
- Total
세조목
최종 프로젝트 2일차(24.03.27) 본문
최종 프로젝트 2일차입니다.
금일은 저희가 어제 선정했던 프로젝트의 주제를 가지고서 어떻게 분석을 해볼지에 대한 이야기를 나눴습니다.

저희가 오늘 고민했던건 '과연 데이터셋을 어떻게 구성해야 클러스터링 모델을 적용시킬 수 있을까' 였습니다.
저희가 생각하고 있는 분석 방법은
- 리뷰 데이터 크롤링
- 긍/부정 분석
- 군집 분석
- 추천
이렇게 총 네가지인데요, 수집한 데이터들을 n개의 카테고리로 나누어서 데이터셋에 넣는게 맞다라고 생각했습니다.
이 때 위 이미지의 좌측 테이블과같이 특성별 컬럼을 만들어 줄 것인지,
우측 테이블처럼 가장 빈도수가 높은 특성 하나만을 특성 컬럼에 넣을 것인지
에 대해서 고민을 했습니다.
이게 무슨 말이냐 하면 만약
'이 집은 청결하고, 빵도 맛있고, 사장님도 친절한데, 직원들은 불친절해요.'
라는 리뷰가 있다고했을때
'청결', '맛있는 빵', '친절함', '불친절함'
이렇게 네개의 특성으로 나눠볼 수 있을 것입니다.
이 때 네 개의 특성을 각각의 컬럼으로 넣어줄 것인지
아니면 네 개의 특성 중 가장 빈도수가 높은 컬럼 하나만을 넣어줄 것인지에 대한 이야기입니다.
튜터님께 질문드려본 결과 좌측 테이블로 구성하는게 맞고,
우측 테이블은 좌측 테이블을 군집 분석했을때의 결과 테이블이 될 것 같다고 하셨습니다.
테이블 구성과 관련된 문제는 해결이 됐고,
다음으로 저희가 고민한건 그럼 어떠한 기준으로 특성을 나눌 것인지와 몇 가지 정도의 특성을 넣을 것인지 였습니다.
다행히 네이버 플레이스에 들어가보면 아래 이미지와같은 특성들을 확인할 수 있기때문에
이 특성들을 활용할 예정입니다.
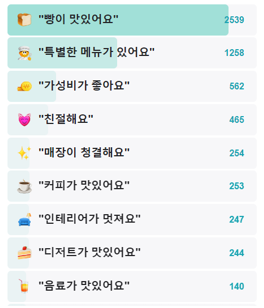
전반적인 청사진이 그려졌으므로 팀원들 각자 크롤링할 사이트를 정하고서
크롤링 작업에 들어갔습니다.
다만 수집해야할 데이터가 워낙 방대하고, 중간에 잘못될 가능성도 있기때문에
시험 삼아 종로구에 한정해서 데이터를 우선적으로 수집해보기로 했습니다.
생각보다 네이버 플레이스 리뷰 데이터 크롤링이 잘 안 되어서 시간이 오래 걸리고 있는데
내일 다시 한번 시도해볼 예정입니다.
'데이터 분석 공부 > 프로젝트' 카테고리의 다른 글
| 최종 프로젝트 4일차(24.03.29) (2) | 2024.03.29 |
|---|---|
| 최종 프로젝트 3일차(24.03.28) (0) | 2024.03.28 |
| 실전 프로젝트 회고 (0) | 2024.03.13 |
| 실전 프로젝트(9일차~12일차) (0) | 2024.03.11 |
| 실전 프로젝트 8일차(24.03.07) (1) | 2024.03.07 |

