
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- data analyst
- jd
- 데이터분석
- Chat GPT
- pandas
- 기초프로젝트
- 군집화
- lambda
- 클러스터링
- 시각화
- da
- 전처리
- streamlit
- SQLD
- If
- 기초통계
- 히트맵
- 데이터 분석
- 서브쿼리
- GA4
- SQL
- 크롤링
- 태블로
- cross join
- 최종 프로젝트
- 프로젝트
- 머신러닝
- Python
- 프롬프트 엔지니어링
- 팀프로젝트
Archives
- Today
- Total
세조목
TIL(Today I Learned) 83일차(24.03.03) 본문
SQLD
서브쿼리
1. 다중 행 서브쿼리
- EXISTS
- 서브쿼리로 어떤 데이터의 존재 여부를 확인하는 것
- EXISTS의 결과는 참/거짓으로 반환됨
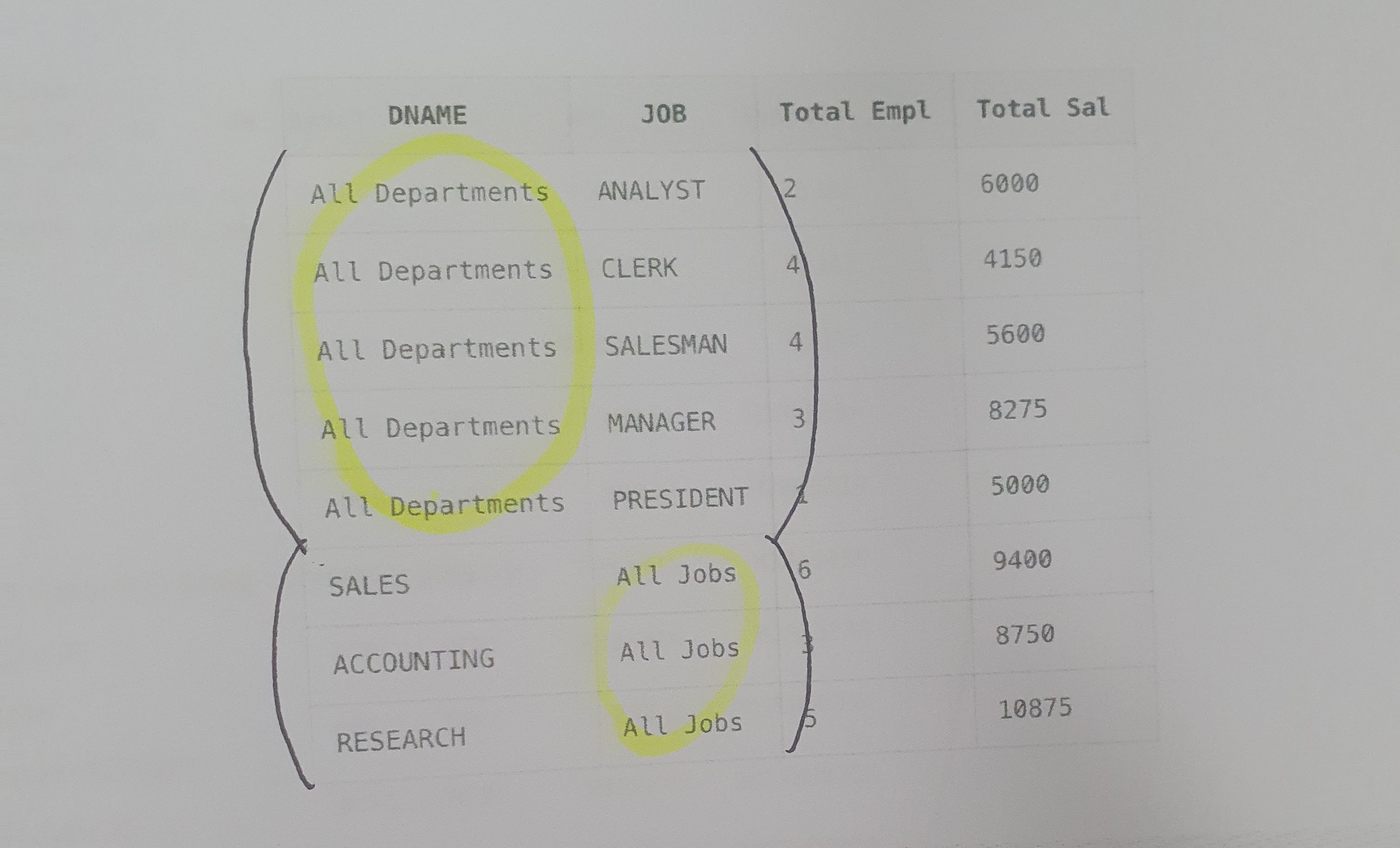
그룹함수
1. ROLLUP
- 각 컬럼의 중간 합계를 만들기 위해 사용하는 함수
- 컬럼의 개수가 N이면 ROLLUP 함수의 결과는 N+1개가 생성됨
- 계층 구조를 가지기때문에 인수의 순서가 바뀌게 되면 수행 결과도 바뀜

2. CUBE
- 결합 가능한 모든 값에 대해 집계를 생성함
- 컬럼의 순서가 바뀌어도 정렬되는 순서는 바뀌지만 데이터의 결과는 동일함
- ROLLUP 함수에 비해서 시스템의 연산 대상이 많음
- 컬럼의 수가 N이라고 가정하면 2^N개의 중간 합계를 생성함

3. GROUPING
- ROLLUP이나 CUBE에 의해서 그룹화된 컬럼의 소계가 계산된 결과를 1로 표시하고, 그 외의 결과는 0으로 표시함
- 소계와 합계로 집계되어 출력된 행을 구분할 때 사용

4. GROUPING SETS
- GROUP BY 문장을 여러 번 반복하지 않아도 다양한 소계 집합을 만들 수 있음
- 결과에 표시된 컬럼들은 서로 평등한 관계이므로 순서가 바뀌어도 결과는 동일함
- ROLLUP, CUBE의 결과물보다 더 명시적임
윈도우 함수
1. 행 순서 관련 함수
- LEAD
- 윈도우에서 특정 위치의 행을 가지고 옴
- 기본값은 1임(기준이 되는 컬럼 다음 행의 값을 가지고 옴)
정규표현식
- 특정한 규칙을 가지고 있는 문자열 집합을 표현하기 위해서 사용되는 형식 언어
- 'regexp'를 사용하면 됨
- REGEXP_LIKE, REGEXP_REPLACE, REGEXP_INSTR, REGEXP_SUBSTR, REGEXP_COUNT가 있음
'데이터 분석 공부 > TIL(Today I Learned)' 카테고리의 다른 글
| TIL(Today I Learned) 85일차(24.03.05) (0) | 2024.03.05 |
|---|---|
| TIL(Today I Learned) 84일차(24.03.04) (0) | 2024.03.04 |
| TIL(Today I Learned) 82일차(24.03.02) (0) | 2024.03.02 |
| TIL(Today I Learned) 81일차(24.03.01) (0) | 2024.03.01 |
| TIL(Today I Learned) 80일차(24.02.29) (1) | 2024.02.29 |
'데이터 분석 공부/TIL(Today I Learned)' Related Articles
more

