
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- cross join
- data analyst
- Python
- lambda
- pandas
- 클러스터링
- 머신러닝
- 군집화
- 프롬프트 엔지니어링
- 최종 프로젝트
- 히트맵
- streamlit
- GA4
- 데이터분석
- SQLD
- 서브쿼리
- Chat GPT
- 팀프로젝트
- If
- 프로젝트
- da
- 데이터 분석
- 전처리
- 태블로
- jd
- SQL
- 크롤링
- 기초통계
- 기초프로젝트
- 시각화
- Today
- Total
세조목
TIL(Today I Learned) 95일차(24.03.20)(feat. 크롤링) 본문
TIL(Today I Learned) 95일차(24.03.20)(feat. 크롤링)
세조목 2024. 3. 20. 21:12크롤링
최종 프로젝트때 활용할 비정형 데이터 분석을 위해 크롤링을 학습하고있으며
현재까지는 requests와 beautifulsoup 라이브러리만을 활용하고 있습니다.


여러가지 예제들을 풀어보면서 학습 중인데
크롤링에 활용되는 코드의 전체 틀은 동일합니다.
그 중 별도로 기록해야겠다싶은 부분을 정리해보려고합니다.
여러개의 클래스에 해당하는 내용 추출하는 방법
1. soup.select("클래스명, 클래스명")
2. soup.find_all(class_=["클래스명", "클래스명"])
strip() 함수 활용
html 코드 작성시
<a href="https://v.daum.net/v/20240320175702320" class="link_txt" data-tiara-layer="article_main" data-tiara-id="20240320175702320" data-tiara-type="harmony" data-tiara-ordnum="14" data-tiara-custom="contentUniqueKey=hamny-20240320175702320&clusterId=5590543,1691287&clusterTitle=[언론사픽] 주요뉴스,경기도 양평군&keywordType=NONE,NONE">
"시차출근제 도입하면 1조3300억원 아낀다"
위와같이 공백이 있기때문에 크롤링 했을때 공백도 함께 끌려온다.
이때 strip()함수를 쓰면 공백을 제거할 수 있다.
li태그 관련
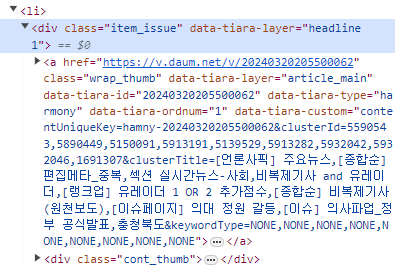
위에서 확인할 수 있는 li 태그를 선택하고싶을때
beautifulsoup의 select(or select_one)메서드의 괄호 안에 'li'를 입력해주면 된다.
.next_element.text
select_one("").next_element.text
next_element는 다음 순번을 가져오는 함수로 strong도 순번에 포함됨
requests.get( ) 관련
requests.get 작성시 괄호 안에
url, headers 뿐만 아니라 cookies와 timeout도 넣을 수 있음
cookies를 입력하면 실제 접속한 것처럼 속일수 있음
원하는 클래스만을 찾고싶을 때
select 작성시 괄호 안에
[class= ] 를 입력하면 내가 찾고자 하는 클래스만을 정확히 찾을 수 있음
'데이터 분석 공부 > TIL(Today I Learned)' 카테고리의 다른 글
| TIL(Today I Learned) 97일차(24.03.22) (0) | 2024.03.22 |
|---|---|
| TIL(Today I Learned) 96일차(24.03.21)(크롤링-selenium, PCA) (0) | 2024.03.21 |
| TIL(Today I Learned) 94일차(24.03.19) (0) | 2024.03.19 |
| TIL(Today I Learned) 93일차(24.03.18) (0) | 2024.03.18 |
| TIL(Today I Learned) 92일차(24.03.15) (0) | 2024.03.15 |


