
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 서브쿼리
- 전처리
- data analyst
- jd
- If
- 히트맵
- cross join
- streamlit
- GA4
- 최종 프로젝트
- 프롬프트 엔지니어링
- Python
- 데이터 분석
- 기초통계
- 군집화
- 프로젝트
- 클러스터링
- 기초프로젝트
- 태블로
- pandas
- Chat GPT
- 데이터분석
- da
- 크롤링
- 팀프로젝트
- SQLD
- 머신러닝
- 시각화
- SQL
- lambda
- Today
- Total
세조목
머신러닝 - 의사결정나무, 랜덤포레스트, KNN, 부스팅 알고리즘(24.02.02) 본문
목차
- 의사결정나무
- 랜덤 포레스트
- KNN(최근접 이웃)
- 부스팅 알고리즘
1. 의사결정나무
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.tree import DecisionTreeClassifier, plot_tree
titanic_df = pd.read_csv('경로.csv')
의사결정나무를 만들려면
sklearn.tree 라이브러리의 DecisionTreeClassifier 클래스를 가져와야한다.
X_features = ['Pclass', 'Sex', 'Age', 'Fare', 'Embarked'] # <- 여기에 다른 변수들 넣어보면서 accuracy, f1 score 올려볼 수 있음
# Pclass, Sex : LabelEncoder
# Age : 결측치 -> 평균으로 대치, 스케일링은 x
titanic_df['Embarked'] = titanic_df['Embarked'].fillna('S')
Age_mean = titanic_df['Age'].mean()
titanic_df['Age'] = titanic_df['Age'].fillna(Age_mean)
le = LabelEncoder()
titanic_df['Sex'] = le.fit_transform(titanic_df['Sex'])
le2 = LabelEncoder()
titanic_df['Pclass'] = le2.fit_transform(titanic_df['Pclass'])
le3 = LabelEncoder()
titanic_df['Embarked'] = le3.fit_transform(titanic_df['Embarked'])
X = titanic_df[X_features]
y = titanic_df['Survived']
model_dt = DecisionTreeClassifier(max_depth = 2, random_state = 42) # max_depth 정해놓지 않으면 무한으로 성장함 / random_state를 고정시켜서 일관된 평가를 할 수 있음
model_dt.fit(X,y)
plt.figure(figsize=(10,5))
plot_tree(model_dt, feature_names=X_features, class_names=['Not Survived', 'Survived'], filled=True)
plt.show()
우선 독립변수로 사용할 컬럼들을 X-features에 넣어주고,
전처리를 시작한다.
Embarked 컬럼의 결측치는 최빈값인 'S'로 넣어주고
Age컬럼의 결측치는 평균값으로 넣어준다.
그런다음 범주형 데이터인 Sex, Pclass, Embarked를 레이블 인코딩해주고
X_features를 변수 X에, 종속변수 Survived컬럼을 변수 y에 넣어준다.
세번째 단계로 DecisionTreeClassifier가 변수 model_dt를 가리키도록 한 후
변수 X, y를 넣어서 학습시킨다.
max_depth와 random_sate의 기능은 다음과 같다.
max_depth는 tree가 얼마나 뻗어져 나갈지를 정해주는 파라미터다.
max_depth를 정해주지 않으면 tree가 무한정 뻗어나가서
컴퓨터 용량을 많이 차지할 수 있으니 왠만하면 지정해주는 것이 좋다.
다음으로 random_state는 나무의 모양을 고정시켜주는 기능으로
고정시키지 않을 경우 test, train으로 나눠서 학습 및 평가를 진행할때
나무의 모양이 달라지면서 평가지수도 함께 달라진다.
따라서 일관된 평가를 위해서는 random_state로 고정시켜주는 것이 좋다.
마지막으로 plt_tree( )에 값들을 집어넣어서
의사결정나무를 출력하면 끝이다.
plt_tree( )에 들어가는 매개변수는
모델, feature_names, class_names, filled이다.
첫번째 파라미터인 모델 자리에는 모델이 저장되어있는 변수(or 모델(ex. DecisionTreeClassifier))을 적어준다.
feature_names에는 독립변수를,
class_names에는 종속변수의 두가지 경우(ex. Survived, not Survived)를
filled에는 boolean 자료형(True, False)가 들어가는데
True를 넣으면 색이 칠해지고, 기본값인 False를 넣으면 무색으로 출력된다.
이 외에도 plot_tree에는 다양한 매개변수들이 존재하며 필요에따라 사용하면 된다.
https://scikit-learn.org/stable/modules/generated/sklearn.tree.plot_tree.html


노드에 적혀있는 단어들을 간략하게 소개하자면
gini
불순도를 나타내는 계수 중 하나이다. 0과 1 사이의 값으로 0에 가까울수록 완벽한 순도를 의미한다. 불순도가 낮아질수록, 다시말해 순도가 높을수록(=0에 가까울수록) 분류가 잘 되었다는 의미이다.
sample
해당 노드의 샘플 개수
value
종속변수에 대한 배열로 앞에서 plot_tree( ) 소괄호 內 class_names에 적은 순서대로 표시된다.
위 예시에서의 경우 class_names = ['Not Survived', 'Survived']로 적었기 때문에
Value = [9, 161]은 9명은 사망, 161명은 생존으로 이해할 수 있다.
class
가장 많은 샘플을 차지하는 클래스를 표현한다.
바로 위에서의 경우 Value = [9, 161]로 생존한 사람이 가장 많기 때문에
Survived로 표시된다.
2. 랜덤포레스트
앞서 살펴본 의사결정나무는 나무가 너무 많이 성장할 경우
과(대)적합 오류에 빠질 가능성이 있다.
여기서 과(대)적합 오류란 특정 모델에서 학습하는 데이터가 너무 많아서
학습했던 모델에만 특화되다보니 해당 모델에서의 성능은 좋지만
다른 모델에서의 성능은 떨어지는 현상을 말한다.
이 문제를 해결하기위해서 랜덤포레스트 모델을 활용할 수 있다.
랜덤포레스트라는 이름에서 알 수 있듯이
나무가 아닌 숲을 만드는 이론이다.
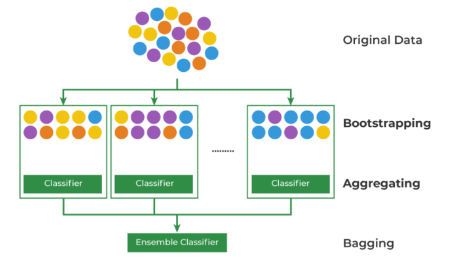
이 이론에는 크게 두 가지 원리가 사용되는데
Bootstrapping과 Aggregating이 그것이다.
먼저 Bootstrapping의 경우 모집단에서 표본을 추출하고,
그 다음번에 추출할 때도 이전 표본에서 추출한 값을 중복으로 뽑을 수 있는
것을 말한다. 이를 데이터 복원 추출이라 한다.
다음으로 Aggregating은 Bootstrapping으로 만든 표본을
하나로 합치는 것을 의미한다.
이렇게 합쳐지는 데이터들은 다수결의 원칙에 따라
최종 결론을 내리게된다.
따라서 의사결정나무의 단점인 과대적합의 오류를 피할 수 있게 되는 것이다.
단점이라고한다면
컴퓨터 리소스 비용이 크며,
여러 표본의 결과값을 한데모아서 하나의 결과값을 추출한 것이기에
어떻게 해서 그 결과값이 나왔는지 해석하는 것이 쉽지 않다는 것이다.
실제로 한번 실습해보자
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score
X_features = ['Pclass', 'Sex', 'Age', 'Fare', 'Embarked']
X = titanic_df[X_features]
y = titanic_df['Survived']
model_lor = LogisticRegression()
model_dt = DecisionTreeClassifier(random_state = 42)
model_rf = RandomForestClassifier(random_state = 42)
model_lor.fit(X,y)
model_dt.fit(X,y)
model_rf.fit(X,y)
y_lor_pred = model_lor.predict(X)
y_dt_pred = model_dt.predict(X)
y_rf_pred = model_rf.predict(X)
def get_score(model_name, y_true, y_pred):
acc = round(accuracy_score(y_true, y_pred),3)
f1 = round(f1_score(y_true, y_pred).round(2),3)
print(model_name, 'acc 스코어는: ', acc, 'f1 스코어는: ', f1)
get_score('lor',y,y_lor_pred)
get_score('dt',y,y_dt_pred)
get_score('rf',y,y_rf_pred)
>>> lor acc 스코어는: 0.79 f1 스코어는: 0.72
>>> dt acc 스코어는: 0.98 f1 스코어는: 0.97
>>> rf acc 스코어는: 0.98 f1 스코어는: 0.97
분류모델로 로지스틱회귀, 의사결정나무, 랜덤포레스트 세가지를 사용해서 각각의 성능을 비교해볼 것이다.
먼저 독립변수와 종속변수를 지정해주고
각각의 라이브러리를 import한 후 변수에 모델을 넣어준다.
이 때 의사결정나무와 랜덤포레스트는 random_state를 적어줌으로써
나무의 모양이 달라지더라도 평가지수는 유지될 수 있도록한다.
다음으로 각각의 모델에 독립변수와 종속변수를 학습시킨 후 예측값을 구한다.
마지막으로 accuracy_score와 f1_score 클래스를 가지고서 정확도와 f1 스코어를 구해본다.
그렇게 했을때 로지스틱회귀, 의사결정나무, 랜덤포레스트 각각의 모델의
정확도와 f1 스코어는 아래와 같다.

lor은 로지스틱 회귀, dt는 의사결정나무, rf는 랜덤포레스트 모델을 의미하며
의사결정나무와 랜덤포레스트의 성능이
로지스틱회귀의 성능보다 좋게 나타났다.
3. KNN(최근접 이웃)
KNN은 K-Nearest Neighbor의 약자로 최근접 이웃이라는 의미다.
* 가장 앞에 있는 K는 주변의 개수를 의미한다.
KNN을 한마디로 표현하자면 '유유상종'이다.
다시말해 비슷한 애들끼리 묶는다는 말이다.

위 이미지를 예로 들자면
만약 K가 3일 경우 K가 3인 범위 안에 들어오는 별과 세모의 개수가
각각 1개, 2개이기때문에 가장 개수가 많은 세모로 판별할 것이고
K가 7일 경우에는 범위 안에 별이 4개, 세모가 3개 들어있기때문에
개수가 가장 많은 별로 판별할 것이다.
여기서 의문사항이 생기는데
바로 K의 값과, 거리(범위)는 어떻게 정하냐는 것이다.
이 의문사항에 답하기 위해서는
'하이퍼 파라미터(Hyper Parameter)라는 개념에 대해서 짚고 넘어가야한다.
먼저 파라미터(Parameter)란 알아서 정해지는 값을 의미한다.
머신러닝 모델이 학습과정에서 추정해서 자동으로 결정되는 값인데
Python에서의 파라미터(=매개변수)와는 다른 의미이므로 주의해야한다.
그렇다면 하이퍼 파라미터(Hyepr Parameter)란 무엇일까?
하이퍼 파라미터란 분석자가 그때 그때 지정해줘야하는 값으로
Data Science라는 이름이 생겨난 이유를 여기서 알 수 있다.
하이퍼 파라미터를 이렇게 저렇게 바꿔가며 좋은 평가지표가 나올때까지
실험을 반복하기때문이다.
앞서 언급했던 K가 바로 이 하이퍼 파라미터이다.
따라서 K는 분석자 또는 데이터 과학자들이 최적의 값이 나올때까지
값을 변경해나가는 것이다.
그렇다면 거리는 어떻게 정할까?
거리는 피타고라스 정리라고도 불리는 유클리드 거리,
맨해튼 거리 등 다양한 거리 계산 방법을 사용해서 구한다.
이 때 단위가 다르면 안 되기 때문에
반드시 표준화(Standardization)가 선행되어야한다.
이같은 KNN은 직관적이고 회귀, 분류 모두 가능하다는 장점이 있지만
차원의 수가 많을수록 계산량이 많아지며 표준화가 필수적이라는 단점이 있다.
4. 부스팅 알고리즘

부스팅 알고리즘은 알고리즘을 여러번 돌리는 것을 의미하는데
그냥 돌리는게 아니라 이전 결과에서 취약했던 부분을 개선하여
다시 알고리즘을 돌리는 것이다.
위 그림을 예시로 들면
첫번째(Weak learner)에서 빨간색 원 하나를 잡아내지 못했기 때문에
해당 부분에 가중치를 두고 한 번 더 알고리즘을 돌린다
그렇게 했을때 두번째(Weak learner)에서는
첫번째에서 포함했던 빨간 원은 제외시켰지만
좌측 하단에 있는 빨간 원 하나를 포함시키게 되었다.
이 두가지 결과를 바탕으로 빨간 원을 모두 제외한
초록 원만을 구분해낼 수 있게 된다.
부스팅 알고리즘은 총 3가지 종류가 있는데
다음과 같다.
- Gradient Boosting Model
- XGBoost
- LightGBM
Gradient Boosting Model은 경사하강법을 통해
가중치 업데이트를 진행하는 방식이다.
다음으로 XGBoost는
병렬학습, 그러니까 동시에 여러 cpu에 일을 시키기때문에
속도가 빠르다는 장점이 있다.
하지만 시간이 오래 걸린다는 단점이 있다.
시간이 오래 걸린다는 XGBoost의 단점을
해결할 수 있는 것이 바로 LightGBM으로
XGBoost보다 학습시간이 짧고 메모리 사용량이 적기때문에
소요되는 시간이 적다는 특징이 있다.
다만 1만건 이하의 데이터로 모델을 돌릴 경우
과적합이 발생할 수 있다.
5. KNN모델 & 부스팅 모델 실습
KNN모델과 부스팅 모델 실습을 한번 진행해보자
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
X_features = ['Pclass', 'Sex', 'Age', 'Fare', 'Embarked']
X = titanic_df[X_features]
y = titanic_df['Survived']
model_knn = KNeighborsClassifier()
model_gbm = GradientBoostingClassifier(random_state=42)
model_xgb = XGBClassifier(random_state=42)
model_lgb = LGBMClassifier(random_state=42)
model_knn.fit(X,y)
model_gbm.fit(X,y)
model_xgb.fit(X,y)
model_lgb.fit(X,y)
y_knn_pred = model_knn.predict(X)
y_gbm_pred = model_gbm.predict(X)
y_xgb_pred = model_xgb.predict(X)
y_lgb_pred = model_lgb.predict(X)
get_score('lor',y,y_lor_pred)
get_score('dt',y,y_dt_pred)
get_score('rf',y,y_rf_pred)
get_score('knn',y,y_knn_pred)
get_score('gbm',y,y_gbm_pred)
get_score('xgb',y,y_xgb_pred)
get_score('lgb',y,y_lgb_pred)
우선 KNN, GradientBoosing, XGBoost, LightGBM 모델을 불러온 후
독립변수와 종속변수를 지정해준다.
그런다음 변수에 모델을 넣어주는데
GradientBoosting, XGBoost, LightGBM 모델은 random_state를 적어줌으로써
나무의 모양이 달라지더라도 평가지수는 유지될 수 있도록한다.
독립변수와 종속변수를 학습시킨 모델을 가지고서 예측을 진행한 후
랜덤 포레스트 모델 실습때 만들어둔 get_score 함수를 가지고서
각각의 모델의 정확도와 f1 스코어를 구한다.

결과값은 위와 같다.
결과상으로는 의사결정나무와 랜덤포레스트의 성능이 가장 좋은 것으로 나타나는데
부스팅 모델들의 경우 데이터의 양이 너무 적을 경우 제 기능을 발휘하지 못하기때문에
성능이 그렇게까지 좋게 나오지 않은 것으로 생각된다.
'데이터 분석 공부 > 머신러닝' 카테고리의 다른 글
| 이커머스 머신러닝 강의 복습(Ch.2 - Logistic Regression) (0) | 2024.02.27 |
|---|---|
| 이커머스 머신러닝 강의 복습(Ch.1 - Linear Regression) (1) | 2024.02.26 |
| 머신러닝 - 전처리(인코딩, 스케일링)에서부터 로지스틱 회귀를 적용한 예측 모델 생성까지(feat. 선형회귀와 로지스틱 회귀의 차이, 스케일링의 정규화와 표준화는 각각 언제 사용하는지)(24.02.. (0) | 2024.02.02 |
| 머신러닝 - 데이터 분리(feat. 과적합)(24.02.01) (0) | 2024.02.01 |
| 머신러닝 - 전처리(인코딩, 스케일링)(24.02.01) (0) | 2024.02.01 |



