
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 프로젝트
- 기초통계
- pandas
- 클러스터링
- 팀프로젝트
- GA4
- da
- If
- 머신러닝
- 최종 프로젝트
- 군집화
- data analyst
- 기초프로젝트
- SQL
- cross join
- 데이터분석
- 태블로
- 데이터 분석
- 히트맵
- 프롬프트 엔지니어링
- lambda
- 시각화
- Chat GPT
- 전처리
- 서브쿼리
- SQLD
- 크롤링
- Python
- streamlit
- jd
- Today
- Total
세조목
머신러닝 - 전처리(인코딩, 스케일링)에서부터 로지스틱 회귀를 적용한 예측 모델 생성까지(feat. 선형회귀와 로지스틱 회귀의 차이, 스케일링의 정규화와 표준화는 각각 언제 사용하는지)(24.02.. 본문
머신러닝 - 전처리(인코딩, 스케일링)에서부터 로지스틱 회귀를 적용한 예측 모델 생성까지(feat. 선형회귀와 로지스틱 회귀의 차이, 스케일링의 정규화와 표준화는 각각 언제 사용하는지)(24.02..
세조목 2024. 2. 2. 17:55Step
- 데이터 불러와서 살펴보기
- Sibsp(자녀수) + Parch(부모수)
- 이상치(Outlier) 처리
- 결측치 처리
- 인코딩(수치형 데이터)
- 스케일링(범주형 데이터)
- 로지스틱회귀(Logistic Regression) / 모델 평가
- test 데이터에 적용
1. 데이터 불러와서 살펴보기
train_df = pd.read_csv('경로/train.csv')
test_df = pd.read_csv('경로/test.csv')
train_df.head(3)
train_df.info()
train_df.describe(include='all')
다양한 컬럼들이 존재하는데
이 중 'Age', 'Fare', 'Family', 'Embarked', 'Pcalss', 'Sex'를 독립변수로
'Survived'를 종속변수로
사용할 것이다.
* Family는 SibSp와 Parch를 더하여 새롭게 추가할 예정으로 다음단계에서 설명한다.
2. Sibsp(자녀수) + Parch(부모수) / 함수명 get_family(df)
train_df_2 = train_df.copy()
def get_family(df):
df['Family'] = df['SibSp'] + df['Parch'] + 1
return df
get_family(train_df_2).head(3)
혹시 모르니 기존 데이터를 새로운 변수(train_df_2)에 저장하고,
자녀(SibSp)컬럼, 부모(Parch)컬럼, 그리고 혼자인 경우도 있으니 1을 더한 값이 저장된
Family 컬럼을 추가하는 함수를 만들어준다.
3. 이상치(Outlier) 처리
pairplot으로 수치형 변수들(Age, Fare, Family)의 이상치를 확인한다.
sns.pairplot(train_df_2[['Age', 'Fare', 'Family']])
Fare컬럼에서 이상치가 존재함에따라 왜도(skew)가 발생하고 있는 것을 확인할 수 있다.

Fare컬럼의 히스토그램만 따로 확인해봤을때 500 부분에 일부 분포해있는 것이 보인다.

Describe함수로 Fare컬럼의 집계값을 확인해본 결과
Fare컬럼의 max값이 대략 512이기때문에 512보다 작은 값들만 추린다.
train_df_2 = train_df_2[train_df_2['Fare'] < 512]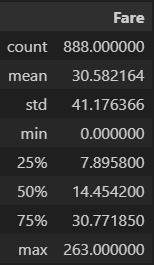
이렇게 했을때 Fare 컬럼의 max값이 263으로 바뀐 것을 확인할 수 있다.
4. 결측치 처리 / 함수명 get_non_missing(df)
train_df_2.isnull().sum()
결측치를 확인한 결과 Age컬럼과 Embarked컬럼에 결측치가 있는 것으로 확인했다(Cabin은 독립변수 아님).
* Fare컬럼의 경우 결측치는 없었지만 수업에서는 같이 결측치 처리를 해주었다.
Age컬럼의 결측치는 평균값으로
Fare컬럼의 결측치는 평균값으로
Embarked컬럼의 결측치는 최빈값인 'S'로
채워준다.
def get_non_missing(df):
Age_mean = train_df_2['Age'].mean()
Fare_mean = train_df_2['Fare'].mean()
df['Age'] = df['Age'].fillna(Age_mean)
df['Fare'] = df['Fare'].fillna(Fare_mena)
df['Embarked'] = df['Embarked'].fillna('S')
return df
5. 인코딩(수치형 데이터) / 함수명 get_numeric_sc(df)
우리가 독립변수로 사용하고자하는 데이터 중
수치형 데이터 컬럼은 Age와 Fare그리고 Family인데
이 컬럼들의 단위는 각각 '살', '원', '명'으로 모두 단위가 다르기때문에
이 단위를 통일시켜주고자
- 표준화(StandardScaler)
- 정규화(MinMax)
해준다.
* Family컬럼은 앞에서 자녀 컬럼(SibSp)과 부모 컬럼(Parch)를 결합해서 만들었음
def get_numeric_sc(def):
from sklearn.preprocessing import StandardScaler, MinMaxScaler
sd_sc = StandardScaler()
mm_sc = MinMaxScaler()
# 표준화
sd_sc.fit(titanic_df_2[['Fare']])
df['Fare_sd_sc'] = sd_sc.transform(df[['Fare']])
# 정규화
mm_sc.fit(titanic_df_2[['Age', 'Family']])
df[['Age_mm_sc', 'Family_mm_sc']] = mm_sc.transform(df[['Age', 'Family']])
return dfFare컬럼은 표준화를,
Age컬럼과 Family컬럼은 정규화를 해준다.
정규화(MinMaxScaler) : 데이터를 특정 범위로 변환하여 범위를 일치시키는 작업
표준화(StandardScaler) : 평균을 0으로, 표준편차를 1로 변환하여 데이터를 조정하는 작업
Fare컬럼과 Age & Family 컬럼을 각각 표준화, 정규화해주는 이유는 다음과 같다.
먼저 Fare컬럼의 경우 이상치를 제거해줬지만 여전히 right skew가 있기때문에
이상치가 있거나 분포가 치우쳐져있을때 유용한 표준화를 적용한다.

다음으로 Age와 Family의 경우 데이터에 이상치가 없고 분포가 크게 치우쳐져있지 않기때문에
이런 경우에 유용한 정규화를 적용시켜준다.
※ 'fit'의 경우 train data에만 적용해주면 됨
6. 스케일링(범주형 데이터) / 함수명 get_category(df)
독립변수 중 Pclass, Sex, 그리고 Embarked는 범주형 데이터기때문에
스케일링(레이블 인코딩, 원핫 인코딩)을 해준다.
- 레이블 인코딩(LabelEncoder)
- 원핫 인코딩(OneHot Encodiner)
def get_category(df):
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
le = LabelEncoder()
le2 = LabelEncoder()
oe = OneHotEncoder()
# 레이블 인코딩
le.fit(titanic_df_2[['Pclass']])
df['Pclass_le'] = let.transform(df['Pclass'])
le2.fit(titanic_df_2[['Sex']]
df['Sex'] = le2.transform(df['Sex'])
df = df.reset_index()
# 원핫 인코딩
oe.fit(titanic_df_2[['Embarked']])
embarked_csr = oe.transform(df[['Embarked']])
embarked_csr_df = pd.DataFrame(embarked_csr.toarray(), columns = oe.get_feature_names_out())
df = pd.concat([df, embarked_csr_df], axis=1)
return dfLabel 인코딩과 OneHot 인코딩 모두
모델을 fit(학습)시키고 transform(변환)시키는건 동일하다.
다만 OneHot 인코딩에서의 경우 레이블 인코딩에서처럼
모델 학습 후 바로 정수 변환시킬 수 있는 것이 아니라
Embarked 컬럼을 배열로 펴서 별도의 데이터프레임을 만들어줘야한다.
이 때 pd.DataFrame과 get_feature_names_out(학습한 클래스의 이름을 나타내는 메서드)사용한다.
그리고 OneHot 인코딩을 하기 전 reset_index()를 해줬는데
reset_index()를 하지 않으면 concat으로 기존 dataframe과
OneHot Encoding한 Embarked 컬럼을 붙일때 에러가 나기 때문이다.
왜 에러가 나는걸까?
앞서 Fare컬럼에서 512보다 큰 값들은 제거해줬는데
index는 그대로 존재하는 상황이다.
그러나 OneHot Encoding된 Embarked 값들은 재정렬된 인덱스
순서대로 기존 데이터프레임에 붙으려고하기때문에
오류가 날 수밖에 없는 것이다.
이해를 돕고자 아래와 같이 이야기해보겠다.
A, B, C가 있었다.
A, B, C의 집은 1, 3, 4였다. <- Encoding 전
A, B, C가 OneHot Encoding이라는 이름의 교육을 다녀왔는데 <- Encoding 후
교육을 받고나니 자기들의 집은 1, 2, 3이라는 인식이 머릿속에 박히게되었다.
A의 경우 1번 집으로 갔다.
B의 경우 원래대로라면 3번 집으로 가야하는데 2번 집으로 가야한다고 인식하고있으니 빈 집을 가게됐고,
C의 경우 원래대로라면 4번 집으로 가야하는데 3번 집으로 가야한다고 인식하고 있으니 다른 집(3번 집)을 가게됐다.
그래서 오류가 발생하는 것이다.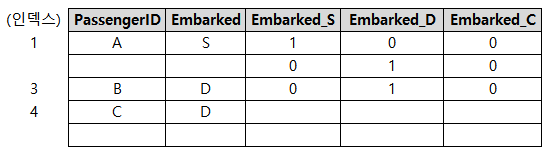
7. 로지스틱회귀(Logistic Regression) / 모델 평가 / 함수명 get_model(df)
다음 단계는 로지스틱 회귀를 가지고서 모델을 평가하는 것이다.
여기서 왜 선형 회귀가 아닌 로지스틱 회귀를 선택했는지에 대한 의문이 들 수 있는데
선형 회귀의 경우 연속적인 종속 변수를 예측할 때 다시말해 실수값을 예측할 때 사용되고,
로지스틱 회귀의 경우 이진분류가 필요할 때 다시말해 인지 아닌지의 여부(0과 1 사이의 확률)를 예측할 때 사용된다.
* 쉽게 이해하기위해 인지 아닌지라고 표현하긴했지만 0, 1 딱 떨어지는 값이 출력되는 것이 아닌 0과 1 사이의 확률값이 출력된다.
우리가 예측하고자하는 종속변수는 Survived 컬럼으로 생존, 사망 두 가지 경우 사이에서의 확률을
예측하고자하는 이진 분류에 해당하기때문에 로지스틱회귀를 사용하는 것이 적절하다.
def get_model(df):
from sklear.linear_model import LogisticRegression
model_lor = LogisticRegression()
X = df[['Age_mm_sc', 'Fare_sd_sc', 'Family_mm_sc', 'Pclass_le', 'Sex_le', 'Embarked_C', 'Embarked_Q', 'Embarked_S']]
y = df[['Survived']]
return model_lor(X,y)로지스틱 회귀 모델을 가져와서
독립변수(X), 종속변수(y)를 지정해준 후
모델에 넣어준다.
model_output = get_model(train_data_2)그렇게 만든 get_model(def) 함수에
지금까지 전처리했던 train_df_2 데이터셋을 넣어서 학습을 시킨다.
이렇게 코드를 작성해놓으면 컴퓨터가
아래 예시 이미지의 빨간 선(예측선)의 각도를
올려도 보고, 낮춰도 보면서 최적의 각도를 찾아낸다.
이렇게 완성된 모델 model_output을 가지고서
train dataset의 Survived 값을 예측해보자
X = df[['Age_mm_sc', 'Fare_sd_sc', 'Family_mm_sc', 'Pclass_le', 'Sex_le', 'Embarked_C', 'Embarked_Q', 'Embarked_S']]
y_pred = model_output.predict(X)
# 평가
from sklearn.metrics import accuracy_score, f1_score
print(accuracy_score(train_df_2['Survived'], y_pred))
print(f1_score(train_df_2['Survived'], y_pred))
>>> 0.8029279279279279
>>> 0.7320061255742726우리가 만든 모델의 정확도는 대략 0.80정도이고,
f1 스코어는 대략 0.73 정도다.
이제 마지막으로 이 모델을 가지고서 test 데이터의 정확도와 f1 score를 평가해보자
8. test 데이터에 적용
앞에서 test 데이터셋은 불러왔으니
test 데이터셋을 이리저리 살펴보자
test_df.head(3)
test_df.info()
test_df.describe(include='all')
그런다음 test dataset을 앞서 우리가 만들어 놓은
함수에 넣어서 모델에 입력해보자
test_df_2 = get_family(test_df)
test_df_2 = get_non_missing(test_df_2)
test_df_2 = get_numeric_sc(test_df_2)
test_df_2 = get_category(test_df_2)get_family는 SibSp 컬럼과 Parch 컬럼을 더해서 Family 컬럼을 만드는 함수이고,
get_non_missing은 결측치를 제거하는 함수다.
Age컬럼과 Fare 컬럼의 결측치에는 각각의 평균값을,
Embarked 컬럼의 결측치에는 최빈값인 'S'를 넣어줬다.
다음으로 get_numeric_sc는 Fare, Age, Family와 같은 수치형 데이터들을 전처리(인코딩)해주는 함수고,
마지막 get_category는 Embarked, Pclass, Sex와 같은 범주형 데이터들을 전처리(스케일링)해주는 함수다.
test_X = test_df_2[['Age_mm_sc', 'Fare_sd_sc', 'Family_mm_sc', 'Pclass_le', 'Sex_le', 'Embarked_C', 'Embarked_Q', 'Embarked_S']]
y_test_pred = model_output.predict(test_X)
from sklearn.metrics import accuracy_score, f1_score
print(accuracy_score(sub_df['Survived'], y_test_pred))
print(f1_score(sub_df['Survived'], y_test_pred))
>>> 0.9425837320574163
>>> 0.9215686274509803이제 독립변수를 지정해준 후 미리 만들어놓은 model_output에 넣어서
예측값을 만들고 정확도와 f1 스코어를 확인해보자
여기서 test dataset이 아닌 sub_df의 값을 예측하는 이유는 아래와 같다.
test dataset을 보면 Survived 컬럼이 없다.

test dataset의 존재 이유는 우리가 만든 모델의 독립변수에
test dataset의 데이터들을 집어넣어 예측값을 만들고
이 예측값이 submission dataset에서 어느정도의 정확도와 f1 score를 보이는지를 확인하기위함이다.
* submission dataset은 캐글에서 제공하는 머신러닝 연습을 위한 Titanic dataset에 포함되어있다.
'데이터 분석 공부 > 머신러닝' 카테고리의 다른 글
| 이커머스 머신러닝 강의 복습(Ch.1 - Linear Regression) (1) | 2024.02.26 |
|---|---|
| 머신러닝 - 의사결정나무, 랜덤포레스트, KNN, 부스팅 알고리즘(24.02.02) (1) | 2024.02.02 |
| 머신러닝 - 데이터 분리(feat. 과적합)(24.02.01) (0) | 2024.02.01 |
| 머신러닝 - 전처리(인코딩, 스케일링)(24.02.01) (0) | 2024.02.01 |
| 머신러닝 - 로지스틱회귀(24.01.31) (0) | 2024.01.31 |



