
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
Tags
- 기초프로젝트
- streamlit
- lambda
- 프롬프트 엔지니어링
- 전처리
- 크롤링
- SQL
- jd
- 태블로
- 머신러닝
- 팀프로젝트
- 군집화
- 클러스터링
- Python
- 시각화
- SQLD
- data analyst
- 프로젝트
- 최종 프로젝트
- 히트맵
- 데이터분석
- If
- da
- 데이터 분석
- GA4
- 서브쿼리
- 기초통계
- pandas
- cross join
- Chat GPT
Archives
- Today
- Total
세조목
심화 프로젝트 6일차(방문 주차에따른 코호트 & 코호트별 weekly 리텐션 구하기)(24.02.11) 본문
1. 코호트 분석에 필요한 컬럼들로 구성된 데이터프레임 만들기
df = train_df2[['date_week', 'fullVisitorId']]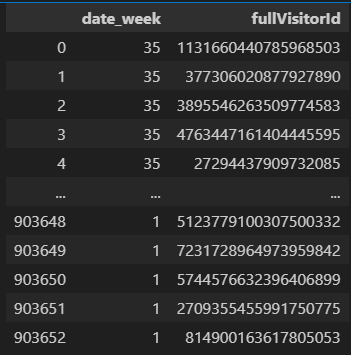
2. 고객ID('fullVisitorId')를 인덱스로 지정하기
df.set_index('fullVisitorId', inplace=True)
# set_index('fullVisitorId') => 'fullVisitorId' 컬럼을 인덱스로 쓰겠다.
# inplace=True => 기존 데이터프레임에 변경된 설정으로 덮어쓰겠다.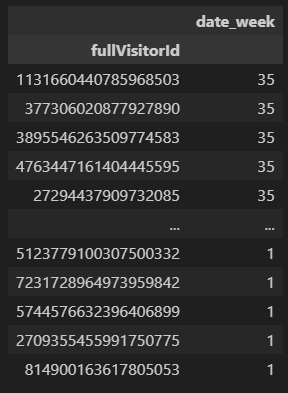
3. df의 인덱스('fullVisitorId')를 기준으로 방문 주차('date_week')의 최소값 구하기
FirstOrder = df.groupby(df.index)['date_week'].min()
df['FirstOrder'] = FirstOrder
# df의 인덱스를 기준으로 'date_week'컬럼의 최소값을 구하겠다.
4. 기존 인덱스('fullVisitorId')를 다시 컬럼으로 올려보내기
df.reset_index(inplace=True)
# 기존에 인덱스로 설정해둔 'fullVisitorId' 인덱스를 제거하고 컬럼에 추가
5. 'FirstOrder'와 'date_week' 기준으로 테이블 만들기
grouped = df.groupby(['FirstOrder', 'date_week'])
# 육안상 달라진건 없음
6. 데이터프레임 grouped의 'fullVisitorId' 컬럼의 고유값 확인
cohorts = grouped['fullVisitorId'].nunique()
7. 시리즈 cohorts의 index를 초기화함
cohorts = cohorts.reset_index()
# 인덱스를 초기화함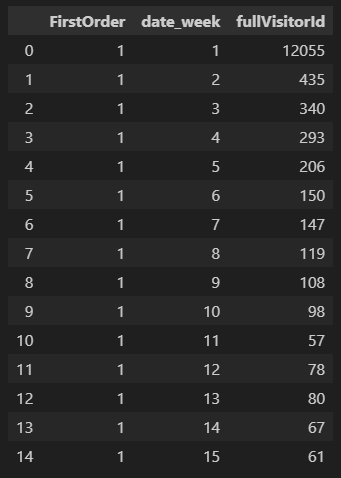
8. 'FirstOrder' 컬럼을 기준으로 컬럼 고유값의 개수를 카운팅하고 인덱스 값을 기준으로 정렬
each_period = cohorts['FirstOrder'].value_counts().sort_index()
# 시리즈 cohorts의 'FirstOrder'컬럼 內 고유값의 개수를 카운팅하고 인덱스 값을 기준으로 값을 정렬시킨다.
# 아래 이미지에서 좌측 컬럼이 'FirstOrder'컬럼이고 우측 컬럼이 고유값의 개수를 나타낸다.
# sort_index()의 기본값은 오름차순이기때문에 'FirstOrder'가 1부터 시작되는 것이다.
9. 구간 나누기
cohortperiod = []
for x in each_period:
for y in range(x):
cohortperiod.append(y)
# cohorts테이블 內 'FirstOrder'컬럼의 고유값의 개수가 담겨있는 each_period 테이블의 값(=주차별로 처음 주문한 주차의 빈도수)
을 range에 넣어서 0부터 해당 값-1 까지를 cohortperiod 리스트에 넣어준다.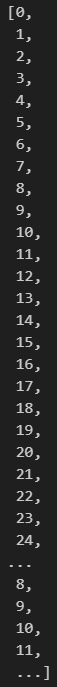
10. 'FirstOrder'와 'CohortPeriod'컬럼을 인덱스로 만들기
cohorts['CohortPeriod'] = cohortperiod
# CohortPeriod 리스트를 cohorts테이블의 컬럼으로 넣어준다.
cohorts.set_index(['FirstOrder', 'CohortPeriod'], inplace = True)
# 'FirstOrder'와 'CohortPeriod' 두 컬럼을 인덱스로 활용한다.
11. 코호트 차트 생성
cohorts=cohorts['fullVisitorId'].unstack(1)
# 함수 unstack은 인덱스를 컬럼으로 올려보내는데 1레벨 인덱스(=두번째 인덱스)인 'CohortPeriod'가 그 대상이다.
# 이 때 출력되는 값은 'fullVisitorId'다.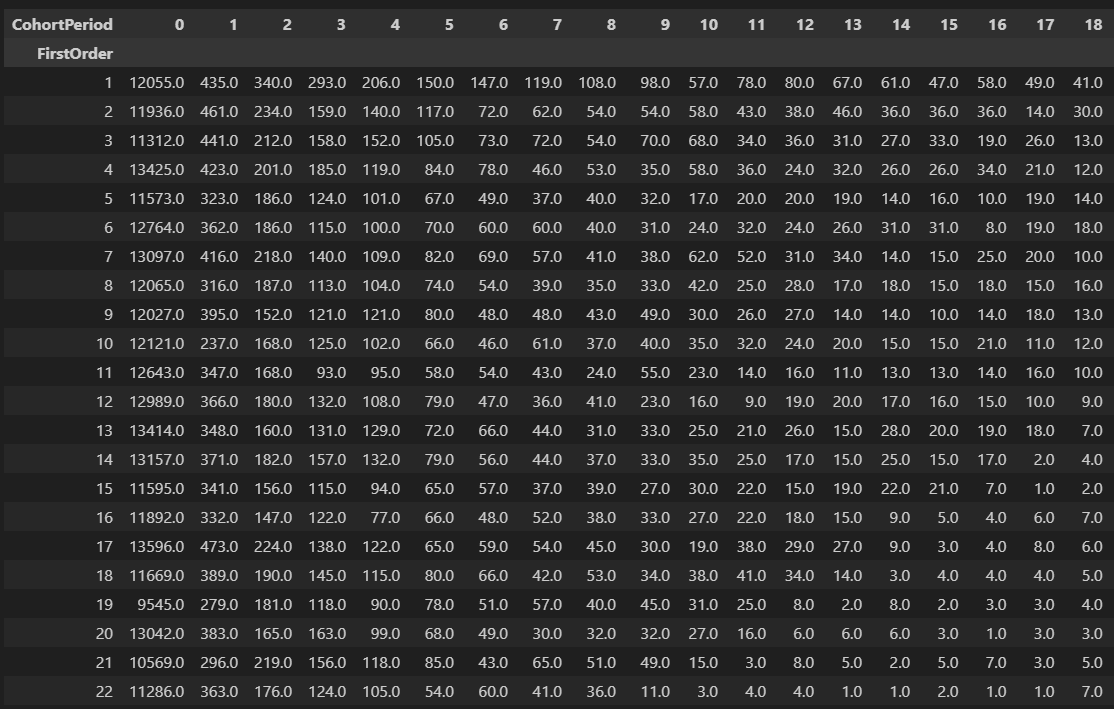
12. 백분율로 표현
user_retention = cohorts.divide(cohorts[0], axis=0)
# cohorts 테이블 內 값들을 cohorts테이블의 0번째(첫번째) 컬럼으로 나누어준다.
# 이때 axis=0은 행을 나눈다는 의미이다.
여기서 'axis=0은 행을 나눈다'는 의미라는 부분이 이해가 잘 안 될수도 있다.
나누고자 하는 값을 행단위로 나눈다고 이해하면 되는데 아래 이미지의 경우
빨간색 테두리 대비 파란색 테두리의 값을 구하는 것이다.

만약 axis를 1로 지정하면 열단위로 나누게되는데
빨간색 테두리의 값을 반바퀴 돌려서 파란색 테두리의 값들을 나눈다고 이해하면 된다.

첫번째 컬럼(0)의 값이 <NA>로 나오는 이유는 첫번째 컬럼의 첫번째 index가 1이기때문에
두번째 컬럼(1)의 값들부터 나누게 되기때문이다.
아래와 같이 말이다.
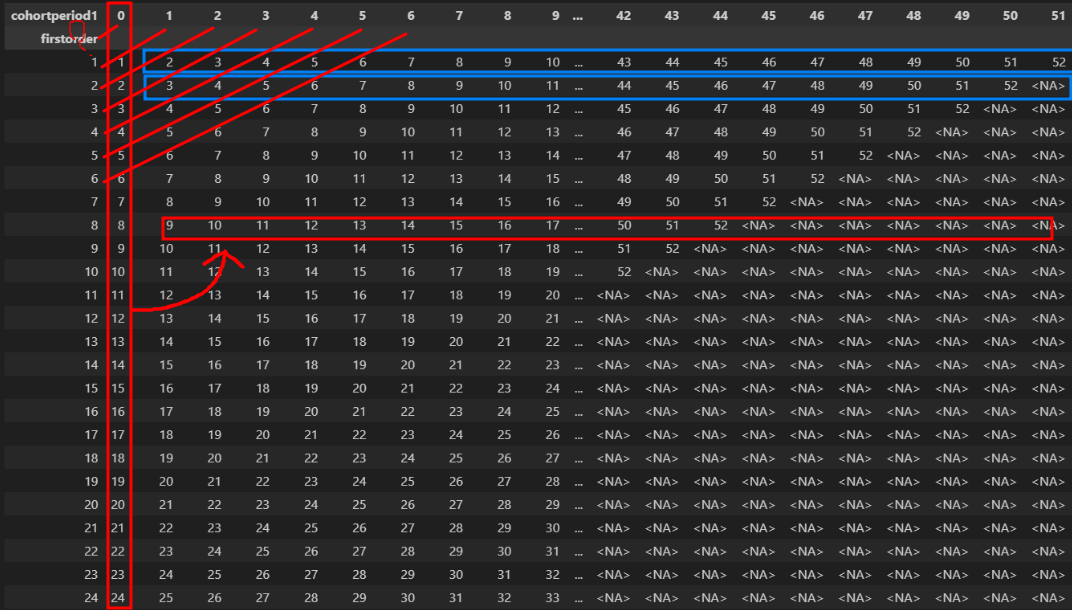
axis를 1로 했을때의 결과값은 아래와 같다.

12. 히트맵으로 표현
plt.figure(figsize=(50,20))
sns.heatmap(data = user_retention, annot=True, fmt='.0%', vmin=0, vmax=0.05, cmap='BuGn')
plt.xlabel('cohortperiod', fontsize=14, labelpad=30)
plt.ylabel('firstorder', fontsize=14, rotation=360, labelpad=40)
plt.yticks(rotation=360)
plt.title('Cohort Analysis', fontsize=50, pad = 30)
plt.show()
'데이터 분석 공부 > 프로젝트' 카테고리의 다른 글
| 심화 프로젝트 8~9일차(24.02.14) (0) | 2024.02.14 |
|---|---|
| 심화프로젝트 7일차(시간별/요일별 사용자수 히트맵)(24.02.12) (1) | 2024.02.12 |
| 심화 프로젝트 4~5일차(DAU, WAU, MAU구하기)(24.02.09~10) (1) | 2024.02.11 |
| 심화 프로젝트 3일차(24.02.08) (0) | 2024.02.08 |
| 심화 프로젝트 2일차(24.02.07) (0) | 2024.02.08 |
'데이터 분석 공부/프로젝트' Related Articles
more



