
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 팀프로젝트
- GA4
- 서브쿼리
- 최종 프로젝트
- If
- da
- 태블로
- 프로젝트
- 데이터분석
- 기초통계
- Python
- 군집화
- 시각화
- data analyst
- 크롤링
- 프롬프트 엔지니어링
- 클러스터링
- SQLD
- 데이터 분석
- 머신러닝
- 히트맵
- pandas
- streamlit
- 기초프로젝트
- cross join
- jd
- 전처리
- Chat GPT
- SQL
- lambda
- Today
- Total
세조목
심화 프로젝트 8~9일차(24.02.14) 본문
심화 프로젝트 8, 9일차에는 아래 To Do 리스트에 따라
ECDF 코드 작성과 CC(Carrying Capacity)계산을 수행했습니다.
<14일까지>
동제 : 케어링 케퍼시티(학습 & 시간 여유 있으면 직접 구해보기)
정희 : ECDF
지훈 : 블랙프라이데이 전주, 블랙프라이데이 주, 블랙플라이데이 그 다음주 ID별 totals 계산
<14일 회의 끝나고>
지훈
1. 16년 8월부터 17년 8월 순서로 바 그래프 그리기
2. 16년 10월, 11월 channelGrouping 별 파이차트
동제
1. 첫 방문자 중 구매한 시점의 분포를 구해보기(for 신규고객 정의)
정희
1. 이탈자 수 counting하기위해 이탈 기간을 어느 정도로 잡는게 적정한지 파악
ECDF 코드 작성
group = train_df2.groupby(['date', 'fullVisitorId'])
result = group.agg({'visitStartTime_UTC_time' : [np.min, np.max]})
result2 = result[result['visitStartTime_UTC_time']['max'] > result['visitStartTime_UTC_time']['min']]
result2.reset_index(inplace=True)
result2['min'] = result2['visitStartTime_UTC_time']['min']
result2['max'] = result2['visitStartTime_UTC_time']['max']
result2['min2'] = result2['min'].apply(lambda x: datetime.strptime(str(x), '%H:%M:%S'))
result2['max2'] = result2['max'].apply(lambda x: datetime.strptime(str(x), '%H:%M:%S'))
result2['max_min_minus'] = result2['max2'] - result2['min2']
result2['max_min_minus'] = result2['max_min_minus'] / pd.Timedelta(1, 'h')
id_max_min_minus_mean = pd.DataFrame(result2.groupby('fullVisitorId')['max_min_minus'].mean())
total_max_min_minus_mean = result2['max_min_minus'].sum() / 47217
ecdf = id_max_min_minus_mean / total_max_min_minus_mean
ecdf.reset_index(inplace=True)
sns.displot(data=ecdf, x='max_min_minus', kind='ecdf')
ECDF(경험적 누적분포 함수)는 위와 같이 코드를 작성했습니다.
하나씩 살펴보겠습니다.
1. 분석 대상 컬럼 그룹화 및 최소, 최대값 계산
group = train_df2.groupby(['date', 'fullVisitorId'])
result = group.agg({'visitStartTime_UTC_time' : [np.min, np.max]})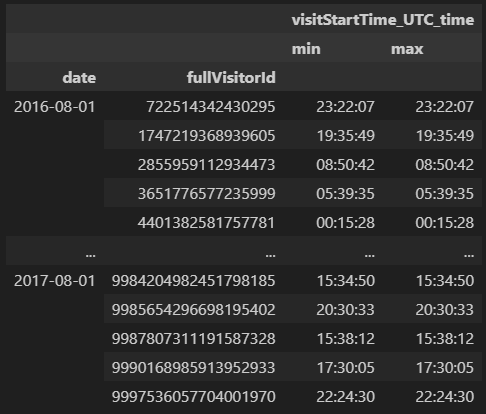
우선 ECDF 분석에 사용될 컬럼인 'date'와 'fullVisitorId' 컬럼을 그룹화해주고,
시간을 나타내는 'visitStartTime_UTC_time' 컬럼의 최소, 최대값을 구해줍니다.
* 'visitStartTime_UTC_time' 컬럼은 연/월/일/시간/분/초가 모든 나와있던 date컬럼의 속성값 中 시간/분/초만 남긴 것입니다.
2. min값보다 max값이 더 큰 값들만 추리기
result2 = result[result['visitStartTime_UTC_time']['max'] > result['visitStartTime_UTC_time']['min']]
result2.reset_index(inplace=True)그런 다음 min값보다 max값이 더 큰 값들만 추려주는데
여기서 의문이 생길 수 있습니다.
'max값이면 당연히 min값보다 큰 거 아니야?'
그러나 실제 데이터를 확인해보면 max값과 min값이 같은 경우가 있기때문에
위와같이 min값보다 max값이 큰 값들을 확실하게 추려줄 필요가 있습니다.
그렇게 min값보다 max값이 큰 값들을 추린 후 인덱스를 초기화해서
인덱스로 사용되고 있던 'date'를 컬럼으로 올려줍니다.
3. min값, max값 별도의 컬럼으로 지정하고 datetime 형식으로 바꾸기
result2['min'] = result2['visitStartTime_UTC_time']['min']
result2['max'] = result2['visitStartTime_UTC_time']['max']
result2['min2'] = result2['min'].apply(lambda x: datetime.strptime(str(x), '%H:%M:%S'))
result2['max2'] = result2['max'].apply(lambda x: datetime.strptime(str(x), '%H:%M:%S'))
result2['max_min_minus'] = result2['max2'] - result2['min2']'visitStartTime_UTC_time' 컬럼 밑으로 들어가있는 min값과 max값을
별도의 컬럼으로 지정해줍니다.
이렇게 해주는 이유는 'visitStartTime_UTC_time' 컬럼 밑으로 들어가있는 min값과 max값은
서로 뺄셈을 할 수 없기때문입니다.
그렇게 별도의 컬럼으로 지정해준 후 뺄셈을 하기위해서
object type인 min과 max컬럼을 datetime형식으로 변경해준 후
뺄셈을 해줍니다.
4. 결과값을 시간 단위로 만들어주기
result2['max_min_minus'] = result2['max_min_minus'] / pd.Timedelta(1, 'h')3단계에서 뺄셈을 하면 '0days~~~'와같이 몇 일의 차이가 나는지까지도 속성값에 포함됩니다.
이를 없애주기위해 'pd.Timedelta(1, 'h')' 로 나누어줌으로써 시간 단위로 출력되게끔합니다.
여기서 'pd.Timedelta(1, 'h')'를 입력하면 아래 이미지에서 확인할 수 있는것처럼
1시간이 출력됩니다.

max와 min의 차이를 1시간으로 나눠주면 'ndays'는 없어지고 시간 단위로 변경이 됩니다.
그렇게 했을때의 결과 테이블은 아래와 같습니다.

5. 유저별 평균 방문시간 계산
id_max_min_minus_mean = pd.DataFrame(result2.groupby('fullVisitorId')['max_min_minus'].mean())
앞서 유저별 max 방문시간과 min 방문시간을 구했으니
이제 평균 방문시간을 구할 차례입니다.
groupby 함수를 활용하여 'fullVisitorId' 컬럼을 기준으로 max와 min값의 차이의 평균을 구해주고
결과값을 데이터프레임 형식으로 변환해줍니다.
6. 데이터셋 전체 평균 방문시간 계산
total_max_min_minus_mean = result2['max_min_minus'].sum() / 47217ECDF의 공식은
유저별 평균 방문시간 / 전체 평균 방문시간
이기때문에
전체 평균 방문시간을 구해줍니다.
7. ECDF 계산
ecdf = id_max_min_minus_mean / total_max_min_minus_mean
ecdf.reset_index(inplace=True)
6번 단계에서 언급했던것처럼
유저별 평균 방문시간을 전체 평균 방문시간으로 나눠준 후
인덱스를 초기화시켜줍니다.
8. ECDF 차트 그리기
sns.displot(data=ecdf, x='max_min_minus', kind='ecdf')
마지막으로 seaborn 라이브러리의 displot을 활용하여
ECDF 차트를 그려줍니다.

차트를 보면 0~1시간 사이의 분포가 가장 많은 것을 확인할 수 있습니다.
CC(Carrying Capacity)
CC는 Carrying Capacity의 약자로
서비스나 제품의 기초 체력을 판별할 수 있는 지표입니다.
New Daily Customers / % Customer You Lost Each Day
위 공식이 CC의 공식으로 신규유입을 이탈률로 나누면 되는데
관련해서는 별도의 포스팅을 통해 좀 더 자세히 설명하겠습니다.
original = train_df2[['date_format', 'fullVisitorId']]
temp = original['date'].dt.year.astype(str) + '-' + original['date'].dt.month.astype(str)
def get_quarter(series):
if series in ['2016-8', '2016-9']:
return 1
elif series in ['2016-10', '2016-11', '2016-12']:
return 2
elif series in ['2017-1', '2017-2', '2017-3']:
return 3
elif series in ['2017-4', '2017-5', '2017-6']:
return 4
elif series in ['2017-7', '2017-8']:
return 5
temp = pd.DataFrame(temp.apply(get_quarter))
original = pd.concat([original, temp], axis=1)
original.columns = ['date', 'id', 'quarter']
# 방문자수
customers_in_one = original[(original['quarter'] == 1)]['id'].nunique()
customers_in_two = original[(original['quarter'] == 2)]['id'].nunique()
customers_in_three = original[(original['quarter'] == 3)]['id'].nunique()
customers_in_four = original[(original['quarter'] == 4)]['id'].nunique()
customers_in_five = original[(original['quarter'] == 5)]['id'].nunique()
print('분기별 유저 수: ', customers_in_one, customers_in_two, customers_in_three, customers_in_four, customers_in_five)
# 신규 유입자
new_come_sixteen_thrid = original[(original['quarter'] == 1)]['id'].nunique()
new_come_sixteen_fourth = original[original['quarter'] == 2][~original['id'].isin(new_come_sixteen_thrid)]['id'].nunique()
new_come_seventeen_first = original[original['quarter'] == 3][~original['id'].isin(new_come_sixteen_thrid) &\
~original['id'].isin(new_come_sixteen_fourth)]['id'].nunique()
new_come_seventeen_second = original[original['quarter'] == 4][~original['id'].isin(new_come_sixteen_thrid) &\
~original['id'].isin(new_come_sixteen_fourth) &\
~original['id'].isin(new_come_seventeen_first)]['id'].nunique()
new_come_seventeen_third = original[original['quarter'] == 5][~original['id'].isin(new_come_sixteen_thrid) &\
~original['id'].isin(new_come_sixteen_fourth) &\
~original['id'].isin(new_come_seventeen_first) &\
~original['id'].isin(new_come_seventeen_second)]['id'].nunique()
print('신규: ', new_come_sixteen_thrid, new_come_sixteen_fourth, new_come_seventeen_first, new_come_seventeen_second, new_come_seventeen_third)
# 이탈자
sixteen_third_churn = original[original['quarter'] == 1][~original['id'].isin(customers_in_two) &\
~original['id'].isin(customers_in_three) &\
~original['id'].isin(customers_in_four) &\
~original['id'].isin(customers_in_five)]['id'].nunique()
sixteen_fourth_churn = original[original['quarter'] == 2][~original['id'].isin(customers_in_three) &\
~original['id'].isin(customers_in_four) &\
~original['id'].isin(customers_in_five)]['id'].nunique()
seventeen_first_churn = original[original['quarter'] == 3][~original['id'].isin(customers_in_four) &\
~original['id'].isin(customers_in_five)]['id'].nunique()
seventeen_second_churn = original[original['quarter'] == 4][~original['id'].isin(customers_in_five)]['id'].nunique()
# 5분기 이탈자 없음
print('이탈: ', sixteen_third_churn, sixteen_fourth_churn, seventeen_first_churn, seventeen_second_churn)
# 각 분기 이탈률
sixteen_third_churn_rate = round(sixteen_third_churn / customers_in_one, 2)
sixteen_fourth_churn_rate = round(sixteen_fourth_churn / customers_in_two, 2)
seventeen_first_churn_rate = round(seventeen_first_churn / customers_in_three, 2)
seventeen_second_churn_rate = round(seventeen_second_churn / customers_in_five, 2)
print('이탈률: ', sixteen_third_churn_rate, sixteen_fourth_churn_rate, seventeen_first_churn_rate, seventeen_second_churn_rate)
# 각 분기 CC
x_third_cc = new_come_sixteen_thrid / sixteen_third_churn_rate
x_fourth_cc = new_come_sixteen_fourth / sixteen_fourth_churn_rate
n_first_cc = new_come_seventeen_first / seventeen_first_churn_rate
n_second_cc = new_come_seventeen_second / seventeen_second_churn_rate
CC = {}
CC['2016-3Q'] = x_third_cc
CC['2016-4Q'] = x_fourth_cc
CC['2017-1Q'] = n_first_cc
CC['2017-2Q'] = n_second_cc
temp = pd.Series(CC)
QAU = {}
QAU['2016-3Q'] = customers_in_one
QAU['2016-4Q'] = customers_in_two
QAU['2017-1Q'] = customers_in_three
QAU['2017-2Q'] = customers_in_four
temp2 = pd.Series(QAU)
res = pd.concat([temp, temp2], axis=1).reset_index()
res.columns = ['quarter', 'carrying capacity', 'QAU']
res = res.melt('quarter', var_name='cc', value_name='고객수' )
import matplotlib.pyplot as plt
g = sns.catplot(x='quarter', y='고객수', hue='cc', data=res, kind='bar')
# extract the matplotlib axes_subplot objects from the FacetGrid
ax = g.facet_axis(0, 0) # or ax = g.axes.flat[0]
# iterate through the axes containers
for c in ax.containers:
labels = [f'{(v.get_height() / 1000):.1f}K' for v in c]
ax.bar_label(c, labels=labels, label_type='edge', padding=1)
저희가 작성한 전체 코드입니다.
1. 구간 나누기
original = train_df2[['date_format', 'fullVisitorId']]
temp = original['date'].dt.year.astype(str) + '-' + original['date'].dt.month.astype(str)
def get_quarter(series):
if series in ['2016-8', '2016-9']:
return 1
elif series in ['2016-10', '2016-11', '2016-12']:
return 2
elif series in ['2017-1', '2017-2', '2017-3']:
return 3
elif series in ['2017-4', '2017-5', '2017-6']:
return 4
elif series in ['2017-7', '2017-8']:
return 5
temp = pd.DataFrame(temp.apply(get_quarter))
original = pd.concat([original, temp], axis=1)
original.columns = ['date', 'id', 'quarter']우선 저희 팀은 CC를 구하는 구간을 분기로 나눴습니다.
분기로 나눈 이유는 16년도 4분기의 방문자수 분포가 눈에 띄게 높았기때문에
분기 단위로 나눠서 보는 것이 좋을 것이라고 판단했기때문입니다.
우선 저희가 사용할 'date'컬럼과 'fullVisitorId'컬럼으로 별도의 테이블을 만들어주고
'date'컬럼에서 연, 월을 뽑아내었습니다(.dt.year & .dt.month 활용).
그리고 1, 2, 3, 4분기에 해당하는 연/월에 분기별 표시를 해주기 위해
별도의 컬럼을 만들어줬는데
하나 하나 수작업으로 할 경우 시간이 오래 걸리기때문에
함수를 만들어 계산했습니다.
이 때 16년과 17년에 3분기가 공통적으로 들어가기때문에
구별해줄 필요가 있었으므로
return 값을 1, 2, 3, 4, 5로 구분했습니다.
그렇게 나온 값을 데이터 프레임으로 변환해준 후
'date'와 'fullVisitorId' 컬럼이 들어있는 데이터프레임과 합쳐줍니다.
2. 신규 유입자 계산
new_come_sixteen_thrid = original[(original['quarter'] == 1)]['id'].nunique()
new_come_sixteen_fourth = original[original['quarter'] == 2][~original['id'].isin(new_come_sixteen_thrid)]['id'].nunique()
new_come_seventeen_first = original[original['quarter'] == 3][~original['id'].isin(new_come_sixteen_thrid) &\
~original['id'].isin(new_come_sixteen_fourth)]['id'].nunique()
new_come_seventeen_second = original[original['quarter'] == 4][~original['id'].isin(new_come_sixteen_thrid) &\
~original['id'].isin(new_come_sixteen_fourth) &\
~original['id'].isin(new_come_seventeen_first)]['id'].nunique()
new_come_seventeen_third = original[original['quarter'] == 5][~original['id'].isin(new_come_sixteen_thrid) &\
~original['id'].isin(new_come_sixteen_fourth) &\
~original['id'].isin(new_come_seventeen_first) &\
~original['id'].isin(new_come_seventeen_second)]['id'].nunique()다음으로 CC 공식의 분자에 들어가는 '신규 유입자'를 구해보았습니다.
저희는 신규 유입자를 이전 분기에는 없었는데 이번 분기에는 있는 사용자로 정의했습니다.
그래서 코드를 보면 16년 4분기의 경우 16년 3분기에는 없는데( !=- 3) 16년 4분기에는 있는( ==2) 값들이라는
조건을 걸어놓은 것을 확인할 수 있습니다.
나머지 분기도 마찬가지로 계산했습니다.
3. 이탈률 계산
# 신규 유입자 카운팅
customers_in_one = original[(original['quarter'] == 1)]['id'].nunique()
customers_in_two = original[(original['quarter'] == 2)]['id'].nunique()
customers_in_three = original[(original['quarter'] == 3)]['id'].nunique()
customers_in_four = original[(original['quarter'] == 4)]['id'].nunique()
customers_in_five = original[(original['quarter'] == 5)]['id'].nunique()
# 이탈자 카운팅
sixteen_third_churn = original[original['quarter'] == 1][~original['id'].isin(customers_in_two) &\
~original['id'].isin(customers_in_three) &\
~original['id'].isin(customers_in_four) &\
~original['id'].isin(customers_in_five)]['id'].nunique()
sixteen_fourth_churn = original[original['quarter'] == 2][~original['id'].isin(customers_in_three) &\
~original['id'].isin(customers_in_four) &\
~original['id'].isin(customers_in_five)]['id'].nunique()
seventeen_first_churn = original[original['quarter'] == 3][~original['id'].isin(customers_in_four) &\
~original['id'].isin(customers_in_five)]['id'].nunique()
seventeen_second_churn = original[original['quarter'] == 4][~original['id'].isin(customers_in_five)]['id'].nunique()
# 이탈률 계산
sixteen_third_churn_rate = round(sixteen_third_churn / customers_in_one, 2)
sixteen_fourth_churn_rate = round(sixteen_fourth_churn / customers_in_two, 2)
seventeen_first_churn_rate = round(seventeen_first_churn / customers_in_three, 2)
seventeen_second_churn_rate = round(seventeen_second_churn / customers_in_five, 2)이탈률에서 이탈자는 이번 분기에는 있었는데 이후 분기에는 없는 사용자로 정의했습니다.
17년 1분기를 예시로 들면 17년 1분기에는 있었는데
17년 2분기와 3분기에는 없는 값들이라는 조건을 걸어준 것을 확인할 수 있습니다.
이렇게 구한 이탈자를 각 분기별 전체 방문자수로 나눠줬습니다.
4. CC 계산
x_third_cc = new_come_sixteen_thrid / sixteen_third_churn_rate
x_fourth_cc = new_come_sixteen_fourth / sixteen_fourth_churn_rate
n_first_cc = new_come_seventeen_first / seventeen_first_churn_rate
n_second_cc = new_come_seventeen_second / seventeen_second_churn_rate그런 다음 2번 단계에서 구한 신규 유입을 3번 단계에서 구한 이탈률로 나눠서 CC를 계산했습니다.
5. 도표 그리기
CC = {}
CC['2016-3Q'] = x_third_cc
CC['2016-4Q'] = x_fourth_cc
CC['2017-1Q'] = n_first_cc
CC['2017-2Q'] = n_second_cc
temp = pd.Series(CC)
QAU = {}
QAU['2016-3Q'] = customers_in_one
QAU['2016-4Q'] = customers_in_two
QAU['2017-1Q'] = customers_in_three
QAU['2017-2Q'] = customers_in_four
temp2 = pd.Series(QAU)
res = pd.concat([temp, temp2], axis=1).reset_index()
res.columns = ['quarter', 'carrying capacity', 'QAU']
res = res.melt('quarter', var_name='cc', value_name='고객수' )
import matplotlib.pyplot as plt
g = sns.catplot(x='quarter', y='고객수', hue='cc', data=res, kind='bar')
# extract the matplotlib axes_subplot objects from the FacetGrid
ax = g.facet_axis(0, 0) # or ax = g.axes.flat[0]
# iterate through the axes containers
for c in ax.containers:
labels = [f'{(v.get_height() / 1000):.1f}K' for v in c]
ax.bar_label(c, labels=labels, label_type='edge', padding=1)그렇게 계산한 CC를 하나의 딕셔너리 형태로 만들어서 라인차트로 표현했는데
위 코드에서 QAU란 Quarter(분기)별 Activated(활성화) Users(사용자)의 약자로
MAU, WAU, DAY 대신 저희 팀이 만든 항목입니다.
원래 QAU라는 항목이 없지만 저희 팀의 경우 분기 단위로 측정을 했기때문에
QAU를 만들 필요가 있었습니다.

※ 코드에서는 catplot을 사용했으나 위 그래프의 경우 bar 그래프입니다.
그렇게 했을때의 CC와 QAU는 공교롭게도 동일한 값이 나왔는데
아무래도 조금 더 코드를 손 보거나, 측정 기준을 달리할 필요성에 대해서
한 번 더 얘기 나눠봐야할 것 같습니다.
'데이터 분석 공부 > 프로젝트' 카테고리의 다른 글
| 심화 프로젝트 11일차(24.02.16) (0) | 2024.02.16 |
|---|---|
| 심화 프로젝트 10일차(24.02.15) (0) | 2024.02.15 |
| 심화프로젝트 7일차(시간별/요일별 사용자수 히트맵)(24.02.12) (1) | 2024.02.12 |
| 심화 프로젝트 6일차(방문 주차에따른 코호트 & 코호트별 weekly 리텐션 구하기)(24.02.11) (0) | 2024.02.11 |
| 심화 프로젝트 4~5일차(DAU, WAU, MAU구하기)(24.02.09~10) (1) | 2024.02.11 |



