
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 서브쿼리
- 팀프로젝트
- 태블로
- 히트맵
- SQL
- data analyst
- 전처리
- 기초프로젝트
- 데이터분석
- 크롤링
- streamlit
- 시각화
- pandas
- da
- 프로젝트
- 기초통계
- Chat GPT
- If
- lambda
- Python
- 머신러닝
- 데이터 분석
- GA4
- 프롬프트 엔지니어링
- 최종 프로젝트
- jd
- 군집화
- 클러스터링
- SQLD
- cross join
- Today
- Total
세조목
최종 프로젝트 13일차(24.04.08) 본문
최종 프로젝트 13일차입니다.
https://teamsparta.notion.site/29b19ca91bd248539e51ed87ff2d5cd1
전처리 진행 상황 | Notion
네이버 : 은평구, 서대문구(완), 마포구(완), 성북구, 종로구, 중구, 동대문구(완), 강남구(완)
teamsparta.notion.site
금일 진행 사항들인데요, 간략하게 정리하자면 아래와 같습니다.
- 페이지별 데이터셋 합치고 전처리 작업 진행
- Review_text 컬럼 결측치 제거
- '시/구' 단위까지만 존재하는 컬럼 삽입
- Review_text 컬럼값의 개행을 띄워쓰기로 대체, Store 컬럼값의 띄워쓰기 제거
- 프랜차이즈 점포 데이터 제거
- 구별 데이터셋 합치기
- 플랫폼별 데이터셋 합치기
- 가게명 통일
- Review_score 결측치 채우기
페이지별 데이터셋 합치고 전처리 작업 진행
0. 페이지별 데이터셋 합치기
가장 먼저 한 작업은 페이지별로 나눠져 있던 데이터셋을 하나로 합치는 작업이었습니다.
# 페이지별 데이터셋 불러오기
df1 = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/before_cleansing/중구/서울 중구 빵_1page_naver.csv")
df2 = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/before_cleansing/중구/서울 중구 빵_2page_naver.csv")
df3 = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/before_cleansing/중구/서울 중구 빵_3page_naver.csv")
df4 = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/before_cleansing/중구/서울 중구 빵_4page_naver.csv")
df5 = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/before_cleansing/중구/서울 중구 빵_5page_naver.csv")
df6 = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/before_cleansing/중구/서울 중구 빵_6page_naver.csv")
# 페이지별 데이터셋 합치기
df = pd.concat([df1,df2])
df = pd.concat([df,df3])
df = pd.concat([df,df4])
df = pd.concat([df,df5])
df = pd.concat([df,df6])
# 인덱스 제거
df.drop('Unnamed: 0', axis=1, inplace=True)
df.reset_index(drop=True, inplace=True)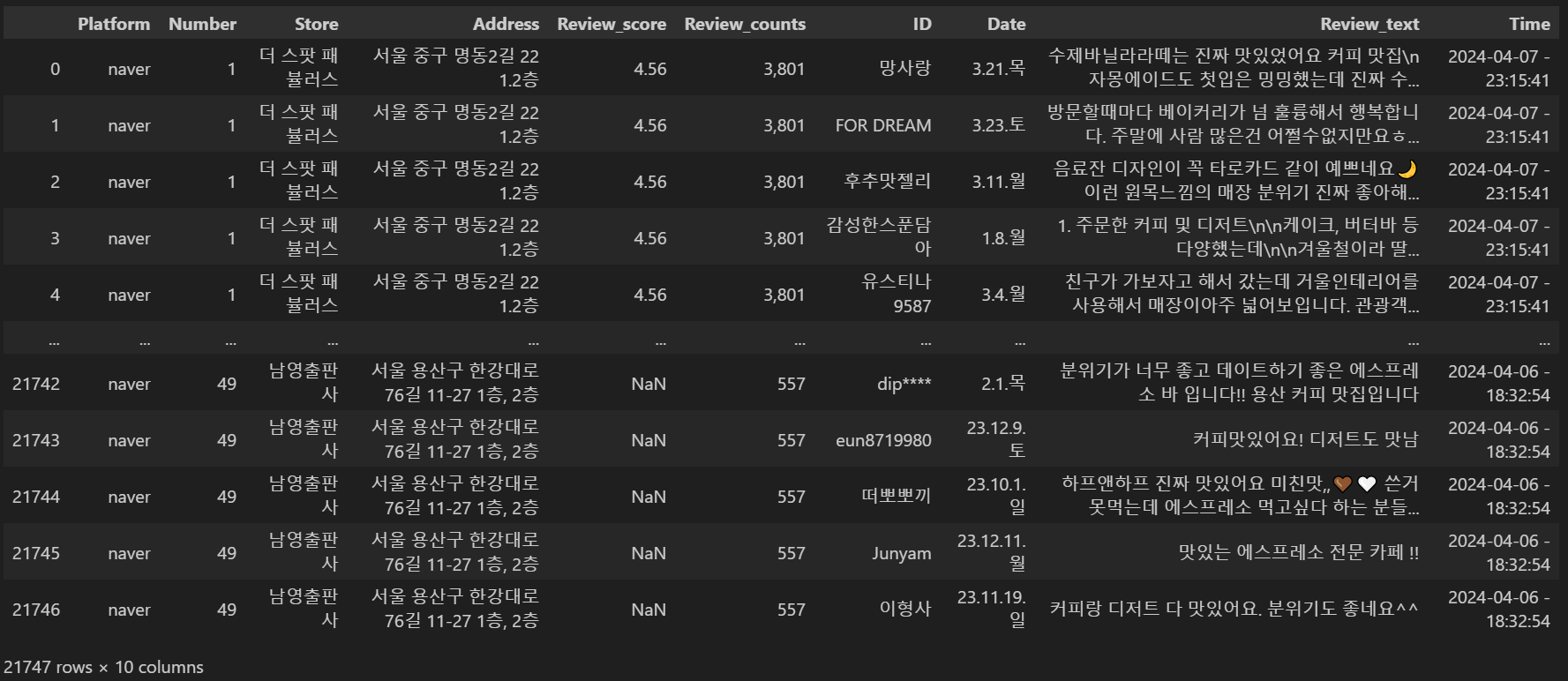
중구의 경우 총 21,747개의 데이터가 존재했습니다.
크롤링 작업이 생각보다 오래 걸렸는데 이렇게 저희가 직접 만든 데이터셋을 보니 밥 안 먹어도 배부른 기분이었습니다.
1. Review_text 컬럼 결측치 제거
2. '시/구' 단위까지만 존재하는 컬럼 삽입
그런 다음 Review_text의 결측치를 '정보없음'으로 채우고,
'시/구'까지만 표시되는 컬럼을 하나 별도로 만들었습니다.
# review_text None값 채우기
df['Review_text'] = df['Review_text'].fillna('정보없음')
# '구' 까지만 존재하는 주소 컬럼 만들기
def slice_to_gu(address):
gu_index = address.find('구') + 1 # find 함수를 사용하면 '구'가 몇 번째 위치에 있는지 알 수 있음
if gu_index:
return address[:gu_index]
else:
return address
df['Addr'] = df['Address'].apply(lambda x: slice_to_gu(x))
df = df[['Platform', 'Number', 'Store', 'Address', 'Addr', 'Review_score', 'Review_counts', 'ID', 'Date', 'Review_text', 'Time']]
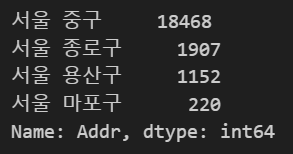
# 다른 구 섞여있는지 여부 확인
df['Addr'].value_counts()
# 타 '구' 제거 필요할 경우에 사용
yongsan = df['Address'].str.contains('용산구').sum()
print(f'용산구에 속한 빵집은 {yongsan}개입니다.')
df = df[~df['Address'].str.contains('용산구')]
# 다른 구 제거 여부 확인
df['Addr'].value_counts()


3. Review_text 컬럼값의 개행을 띄워쓰기로 대체, Store 컬럼값의 띄워쓰기 제거
Review_text 컬럼값에 개행이 있으면 긍/부정 지수 추출이 힘들기 때문에 개행을 띄워쓰기로 대체했으며
Store 컬럼값의 경우는 정렬을 용이하게 하기위해서 띄워쓰기를 없앴습니다.
3번 작업의 경우 편리하게 하기위해 함수를 만들어서 활용했습니다.
def to_str(text):
text = str(text)
return text
def remove_newline(text):
text = text.replace("\n", "" "")
return text
def remove_space(text):
text = text.replace(" ", "")
return text
df['Store'] = df['Store'].apply(lambda x : to_str(x))
df['Review_text'] = df['Review_text'].apply(lambda x : to_str(x))
df['Store'] = df['Store'].apply(lambda x : remove_space(x))
df['Review_text'] = df['Review_text'].apply(lambda x : remove_newline(x))
4. 프랜차이즈 점포 데이터 제거
일반적으로 무언가를 추천할 때 프랜차이즈 가게를 추천하는 경우는 많지 않기때문에
프랜차이즈 점포들은 모두 제외했습니다.
# 프랜차이즈 회사 개수 확인
paris_num = df['Store'].str.contains('파리바게뜨').sum()
tous_num = df['Store'].str.contains('뚜레쥬르').sum()
starbucks_num = df['Store'].str.contains('스타벅스').sum()
paik_num = df['Store'].str.contains('빽다방').sum()
mega_num = df['Store'].str.contains('메가').sum()
hollys_num = df['Store'].str.contains('할리스').sum()
coffine_num = df['Store'].str.contains('커핀').sum()
dunkin_num = df['Store'].str.contains('던킨').sum()
twosome_num = df['Store'].str.contains('투썸').sum()
ediya_num = df['Store'].str.contains('이디야').sum()
dessert39_num = df['Store'].str.contains('디저트39').sum()
angel_num = df['Store'].str.contains('엔제리너스').sum()
compose_num = df['Store'].str.contains('컴포즈').sum()
goncha_num = df['Store'].str.contains('공차').sum()
paul_num = df['Store'].str.contains('바셋').sum()
print(f'파리바게뜨는 {paris_num}개입니다.')
print(f'뚜레쥬르는 {tous_num}개입니다.')
print(f'스타벅스는 {starbucks_num}개입니다.')
print(f'빽다방은 {paik_num}개입니다.')
print(f'메가커피는 {mega_num}개입니다.')
print(f'할리스는 {hollys_num}개입니다.')
print(f'커핀그루나루는 {coffine_num}개입니다.')
print(f'던킨도너츠는 {dunkin_num}개입니다.')
print(f'투썸플레이스는 {twosome_num}개입니다.')
print(f'이디야는 {ediya_num}개입니다.')
print(f'디저트39는 {dessert39_num}개입니다.')
print(f'엔제리너스는 {angel_num}개입니다.')
print(f'컴포즈커피는 {compose_num}개입니다.')
print(f'공차는 {goncha_num}개입니다.')
print(f'폴바셋은 {paul_num}개입니다.')
저희가 제외하기로 정한 프랜차이즈는 총 15개입니다.
'구'별 데이터셋에 총 몇 개의 프랜차이즈 점포가 있는지 먼저 확인했습니다.
df = df[~df['Store'].str.contains('파리바게뜨')]
df = df[~df['Store'].str.contains('뚜레쥬르')]
df = df[~df['Store'].str.contains('스타벅스')]
df = df[~df['Store'].str.contains('빽다방')]
df = df[~df['Store'].str.contains('메가')]
df = df[~df['Store'].str.contains('할리스')]
df = df[~df['Store'].str.contains('커핀')]
df = df[~df['Store'].str.contains('던킨')]
df = df[~df['Store'].str.contains('투썸')]
df = df[~df['Store'].str.contains('이디야')]
df = df[~df['Store'].str.contains('디저트39')]
df = df[~df['Store'].str.contains('엔제리너스')]
df = df[~df['Store'].str.contains('컴포즈')]
df = df[~df['Store'].str.contains('공차')]
df = df[~df['Store'].str.contains('바셋')]그런 다음 데이터셋에서 프랜차이즈 점포의 이름을 포함하고 있는 Store 컬럼의 값들을 모두 제거해주었습니다.
구별 데이터셋 합치기
# 구별 데이터셋 불러오기
gangnam = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/before_cleansing/강남/naver_gangnam.csv")
dongdaemun = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/before_cleansing/동대문/naver_dongdaemun.csv")
mapo = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/before_cleansing/마포/naver_mapo.csv")
seodaemun = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/before_cleansing/서대문/naver_seodaemun.csv")
seongbuk = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/before_cleansing/성북/naver_seongbuk.csv")
eunpyeong = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/before_cleansing/은평/naver_eunpyeong.csv")
jongro = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/before_cleansing/종로/naver_jongro.csv")
jungu = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/before_cleansing/중구/naver_jungu.csv")
# 구별 데이터셋 합치기
seoul = pd.concat([gangnam,dongdaemun])
seoul = pd.concat([seoul,mapo])
seoul = pd.concat([seoul,seodaemun])
seoul = pd.concat([seoul,seongbuk])
seoul = pd.concat([seoul,eunpyeong])
seoul = pd.concat([seoul,jongro])
seoul = pd.concat([seoul,jungu])
# 데이터셋 복사(대비)
seoul2 = seoul.copy()
# Store별 numbering 작업
seoul2['Number'] = pd.factorize(seoul['Store'])[0] + 1
seoul2 = seoul2[['Platform', 'Number', 'Store', 'Address', 'Addr', 'Review_score', 'Review_counts', 'ID', 'Date', 'Review_text', 'Time']]
플랫폼별 데이터셋 합치기
Naver, Google, Kakao 3개 플랫폼의 데이터셋 전처리 작업이 모두 끝난 후
플랫폼별 데이터셋을 모두 합쳤습니다.

3사 데이터셋 모두 합치니 193,234개 정도의 데이터가 있었습니다.
가게명 통일
같은 주소지에 있는 같은 가게인 플랫폼마다 가게명이 다른 경우가 있었습니다.
그래서 가게명을 통일시켜주는 작업을 진행했는데요,
하나 하나 확인하면서 진행해야하다보니 전체 파일을 팀원 수(4명)로 나눠서
각자 한 개 파일씩 맡아서 작업을 진행했습니다.
total = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/after_cleansing/total_2.csv")
total.drop('Unnamed: 0', axis=1, inplace=True)
# 단순 변경
total['Store'] = total['Store'].replace("삼송빵집코엑스점", "삼송빵집스타필드코엑스몰점")
# 조건이 두 개 이상인 경우
total.loc[(total['Platform'] == 'Google') & (total['Address'] == '서울특별시 동대문구 휘경동 321-7'), 'Store'] = '뽀르뚜아경희대점'
빵집 이름만 변경하면 되는 경우가 대부분이긴 했는데
간혹 특정 플랫폼, 특정 주소의 가게명을 수정해야하는 경우가 있어서
그 때는 위 코드 중 세번째 단락 코드와같이 2개의 조건을 부여해서 가게명을 변경했습니다.

이렇게 한 쪽에는 ipynb파일을,
다른 한 쪽에는 csv파일을 띄워두고
어느 가게명이 다른지 확인, 수정 작업을 진행했습니다.
Review_score 결측치 채우기
마지막으로 Review_score(평점) 채우기 작업을 진행했습니다.
total = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/after_cleansing/total_2.csv")
total.drop('Unnamed: 0', axis=1, inplace=True)
total.loc[total['Address']=='서울 종로구 서순라길 89-15 솔방울', 'Review_score'] = 4.6
total[total['Address']=='서울 종로구 서순라길 89-15 솔방울']
다른 플랫폼에 평점이 있을 경우 플랫폼들의 평점 평균을 대신 사용하고,
모든 플랫폼에서 평점이 없을 경우에는 해당 가게가 속해있는 '구'의 평점 평균을 사용하기로했습니다.
'구'의 평점 평균은 모든 데이터셋을 하나로 합친 다음에야 확인할 수 있기때문에
플랫폼별 평점 평균을 우선적으로 계산했습니다.
위 코드에 적혀있는 주소는 평점이 없는 가게가 속해있는 주소지인데요,
플랫폼마다 주소가 다르기 때문에 평점이 없는 플랫폼의 주소를 적어주고,
그 플랫폼에 등록되어있는 가게의 평점에 평균값을 넣어줍니다.
팀원 모두 Review_score 전처리 작업까지만 진행했고,
- 내일은 dataset을 합친 후 Review_score 결측치에 '구'별 평균값 넣기와
- Review_counts(리뷰수) 콤마 제거하기
- 경사도 컬럼 추가
- 긍/부정 지수 및 특성 지수 부여
이렇게 네 가지 작업을 진행할 예정입니다.
'데이터 분석 공부 > 프로젝트' 카테고리의 다른 글
| 최종 프로젝트 15~16일차(24.04.10~11) (0) | 2024.04.11 |
|---|---|
| 최종 프로젝트 14일차(24.04.09) (0) | 2024.04.09 |
| 최종 프로젝트 11일~12일차(24.04.06~07) (1) | 2024.04.07 |
| 최종 프로젝트 10일차(24.04.05) (0) | 2024.04.05 |
| 최종 프로젝트 8일차(24.04.03) (0) | 2024.04.03 |



