
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 기초통계
- 데이터분석
- 히트맵
- 크롤링
- 시각화
- 머신러닝
- 태블로
- 프롬프트 엔지니어링
- lambda
- streamlit
- Chat GPT
- 클러스터링
- 최종 프로젝트
- pandas
- 팀프로젝트
- 프로젝트
- 서브쿼리
- data analyst
- da
- cross join
- jd
- 전처리
- Python
- 군집화
- 데이터 분석
- SQLD
- If
- GA4
- 기초프로젝트
- SQL
- Today
- Total
세조목
최종 프로젝트 14일차(24.04.09) 본문
최종 프로젝트 14일차입니다.
금일은
- Review_score 전처리 작업 끝난 데이터셋 통합
- 전처리 작업
- '구' 평균 평점으로 평점 결측치 채우기
- Review_count 컬럼값 콤마 & .0 지우기
- 주소 변경
- 경사도 추가
- GPT API 코드 작성
- GPT 프롬프트 고민
를 진행했습니다.
Review_score 전처리 작업 끝난 데이터셋 통합
Review_score 결측치 처리 작업이 어제부로 끝났습니다.
전체 파일을 1/4해서 파일 한 개당 팀원 한 명이 붙어서 작업을 했다보니
파일을 다시 통합할 필요가 있었습니다.
# 페이지별 데이터셋 불러오기
total_1 = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/after_cleansing/통합본/total_1_after_cleansing.csv")
total_2 = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/after_cleansing/통합본/total_2_after_cleansing.csv")
total_3 = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/after_cleansing/통합본/total_3_after_cleansing.csv")
total_4 = pd.read_csv("N:/개인/DA/Python/크롤링/final_project/after_cleansing/통합본/total_4_after_cleansing.csv")
# 페이지별 데이터셋 합치기
total = pd.concat([total_1,total_2])
total = pd.concat([total,total_3])
total = pd.concat([total,total_4])
# Time 컬럼 결측치 작업
total['Time'] = total['Time'].fillna('정보없음')
# Unnamed: 0(인덱스) 컬럼 지우기
total.drop('Unnamed: 0', axis=1, inplace=True)
# Store별 numbering 작업
total['Number'] = pd.factorize(total['Store'])[0] + 1
전처리 작업
1. '구' 평균 평점으로 평점 결측치 채우기
어제 진행했던 평점 결측치 처리 작업은 한 개 store가 여러 플랫폼에 등록되어있고,
어떠한 플랫폼에라도 평점이 기재되어있는 경우 해당 평점으로 결측치를 채우는 작업이었습니다.
모든 플랫폼에 평점이 기재되어있지 않은 경우는 데이터셋을 모두 통합한 후
store가 속한 '구' 전체 평점 평균으로 채우기로 했습니다.
# '구' 평점 평균 확인
total.groupby('Addr')['Review_score'].mean()
우선 '구'의 평점 평균을 확인했습니다.
# '구' 평점 평균으로 결측치 채우기
total.loc[(total['Addr']=='서울 강남구') & (total['Review_score'].isna()), 'Review_score'] = 4.3
total.loc[(total['Addr']=='서울 동대문구') & (total['Review_score'].isna()), 'Review_score'] = 4.4
total.loc[(total['Addr']=='서울 마포구') & (total['Review_score'].isna()), 'Review_score'] = 4.4
total.loc[(total['Addr']=='서울 서대문구') & (total['Review_score'].isna()), 'Review_score'] = 4.4
total.loc[(total['Addr']=='서울 성북구') & (total['Review_score'].isna()), 'Review_score'] = 4.3
total.loc[(total['Addr']=='서울 은평구') & (total['Review_score'].isna()), 'Review_score'] = 4.5
total.loc[(total['Addr']=='서울 종로구') & (total['Review_score'].isna()), 'Review_score'] = 4.3
total.loc[(total['Addr']=='서울 중구') & (total['Review_score'].isna()), 'Review_score'] = 4.3그런 다음 각각의 '구'의 Review_score 결측치를 앞서 확인한 '구'별 평점 평균으로 채웠습니다.
2. Review_count 컬럼값 콤마 & .0 지우기
# 콤마 지우기
def remove_comma(value):
value = str(value)
if value.find(','):
value = value.replace(',', '')
return value
total['Review_counts'] = total['Review_counts'].apply(lambda x: remove_comma(x))
# .0 지우기
def to_float(value):
value = float(value)
return value
def remove_dot_zero(value):
if isinstance(value, float) and value.is_integer():
return int(value)
return value
total['Review_counts'] = total['Review_counts'].apply(to_float)
total['Review_counts'] = total['Review_counts'].apply(remove_dot_zero)Review_counts 컬럼값을 보면 종종 콤마가 들어있는 경우가 있었습니다.
그런데 콤마를 남겨둘 경우 차후 클러스터링 작업을 원활하게 진행할 수 없기때문에
콤마를 제거해주는 작업을 했습니다.
Review_counts의 컬럼값들 중 소수점 값들도 일부 남아있었는데
위와 같은 이유로 함께 제거했습니다.
저의 경우 소수점을 지우기 위해 기존 값을 float type으로 변경한 후,
그 값이 부동소수점 수이면서 정수인지를 확인하여 참값이라면
정수(int)로 변경해줍니다.
그렇게 정수로 변경해주면 정수이기때문에 소수점 아래 자리가 사라지게됩니다.
3. 주소 변경
주소값들 중 잘못 기재되어있는 값들이 4개 정도 보였습니다.
1. 우측 24-68번지 KR 서울특별시 은평구 구산동 호 대광빌딩 1층
2. 우측 KR 서울특별시 은평구 응암동 103-35번지 1층 2호
3. 상가1층 333 KR 서울특별시 종로구 종로구 종로 크로도(crodo
4. 필지 KR 서울특별시 서대문구 연희동 188-55번지 1층 외1호 현빌딩위와같이 지도에 검색했을때 검색 결과를 확인할 수 없는 주소였습니다.
total_with_slope.loc[total_with_slope['Address']=='우측 24-68번지 KR 서울특별시 은평구 구산동 호 대광빌딩 1층', 'Address']='서울특별시 은평구 구산동 24-68'
total_with_slope.loc[total_with_slope['Address']=='우측 KR 서울특별시 은평구 응암동 103-35번지 1층 2호', 'Address']='서울특별시 은평구 응암동 103-35번지 1층 2호'
total_with_slope.loc[total_with_slope['Address']=='상가1층 333 KR 서울특별시 종로구 종로구 종로 크로도(crodo', 'Address']='서울특별시 은평구 응암동 103-35번지 1층 2호'
total_with_slope.loc[total_with_slope['Address']=='필지 KR 서울특별시 서대문구 연희동 188-55번지 1층 외1호 현빌딩', 'Address']='서울특별시 서대문구 연희동 188-55번지 1층'해당 주소들의 원 주소를 확인한 후
위와같이 코드를 작성하여 수정해주었습니다.
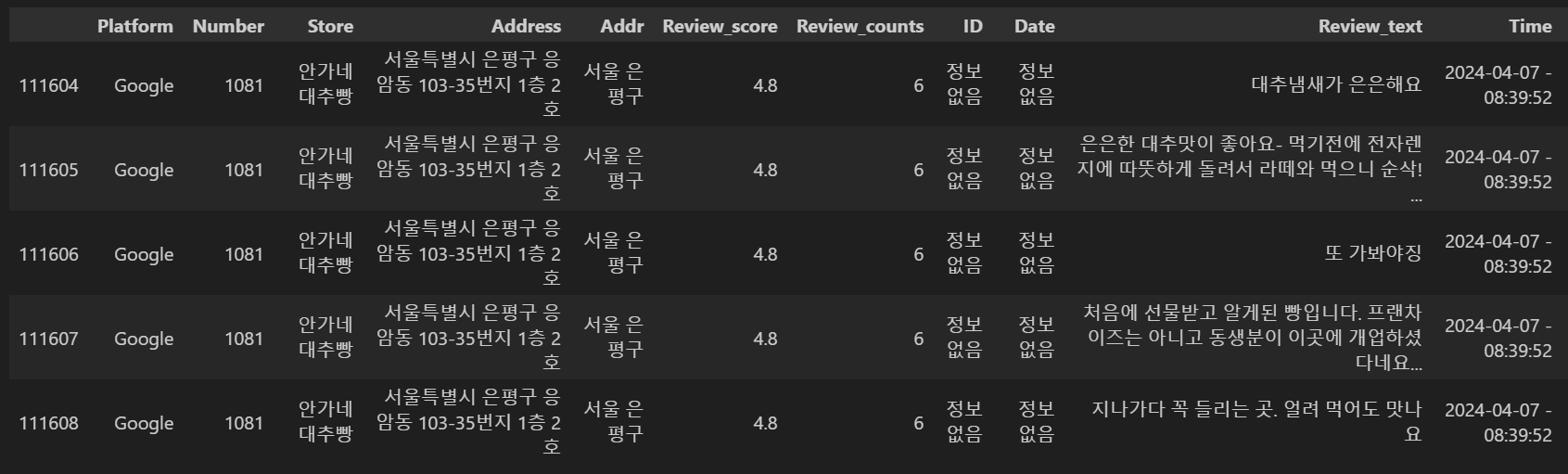
3. 경사도 추가
저희는 클러스터링 작업을 진행할 때 '경사도'도 하나의 차원으로 사용할 예정이기때문에
'경사도'를 추가하는 작업을 진행했습니다.
이 때는 QGIS 프로그램을 활용했습니다.

QGIS는 지리 정보 처리 시스템 중 하나로
ArcGIS와 양대산맥을 이루는데 무료이다보니 많은 사람들이 이용하고있습니다.
이번 작업을 진행할 때 사용했던 파일은
서울시 DEM(Digital Elevation Model) 래스터 레이어와
가게별 주소지가 기록되어있는 벡터 레이어였습니다.
먼저 가게별 주소지가 기록된 벡터 레이어를 만들기위해
python에서 가게명의 고유값만을 추출할 필요가 있었습니다.
# Store 컬럼 고유값 추출
total_unique = total.drop_duplicates(subset=['Store'])drop_duplicates 메서드를 활용하면 간단하게 고유값을 추출할 수 있습니다.
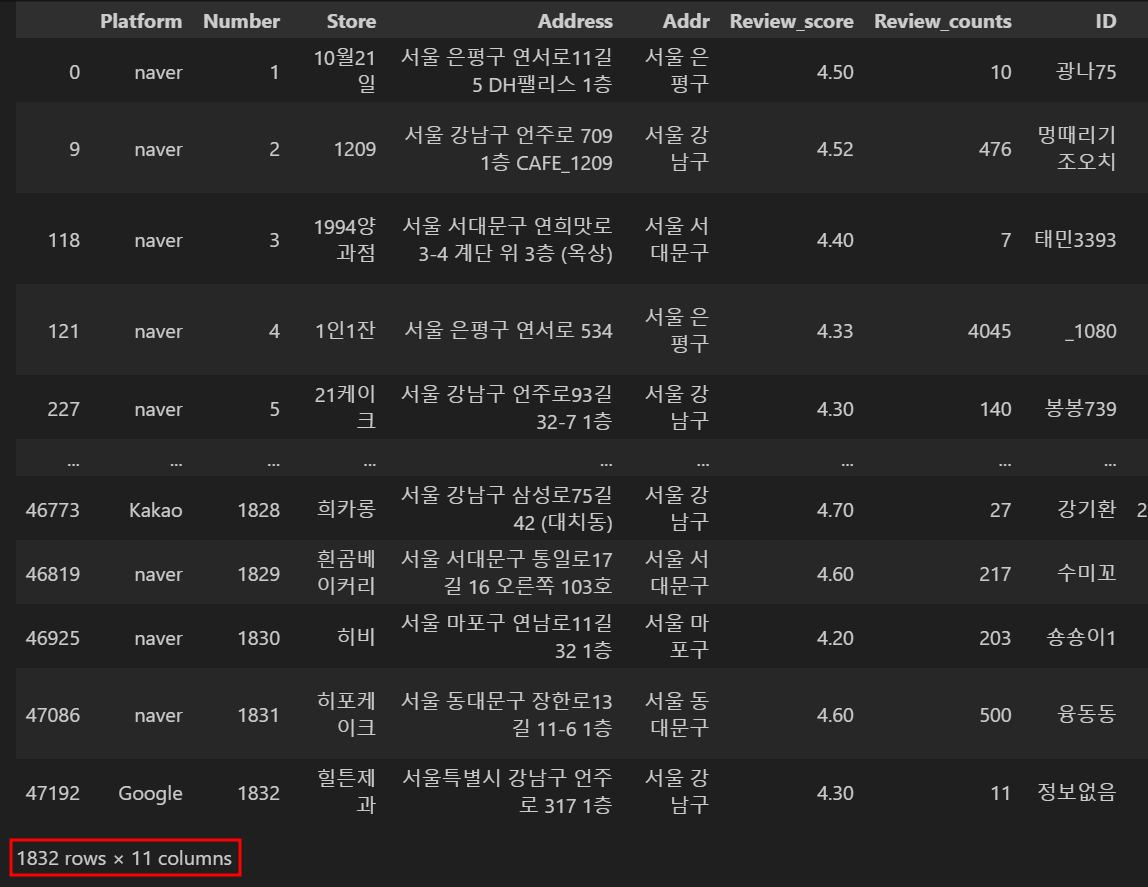
전체 188,776건의 데이터 중 1,832건의 데이터만 추출했습니다.
# csv파일 내보내기
total_unique.to_csv('total_unique.csv', encoding = "utf-8-sig")그런 다음 QGIS 파일에서 작업하기위해 CSV파일로 내보냈습니다.
추출한 CSV파일에는 가게들의 주소지가 입력되어있는데요,
QGIS에서 작업하기위해서는 경, 위도 좌표가 필요합니다.
이 때 사용하는 프로그램이 Geocoding Tool입니다.
하루에 최대 1만건까지는 무료로 좌표 변환을 할 수 있기때문에
저희가 변환해야하는 1,832건은 문제 없이 변환할 수 있었습니다.
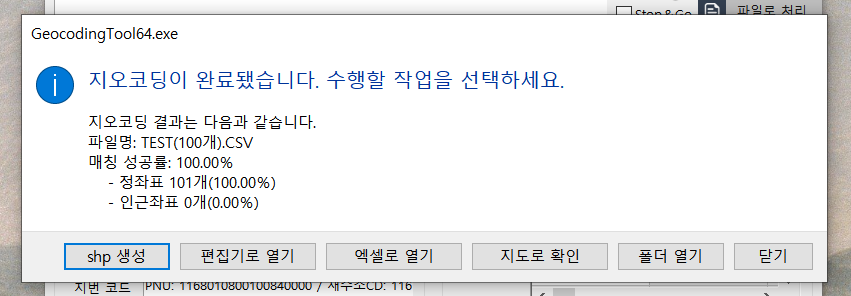
경, 위도 좌표 추가가 완료되면 위와 같이 shp 생성 버튼이 활성화됩니다.
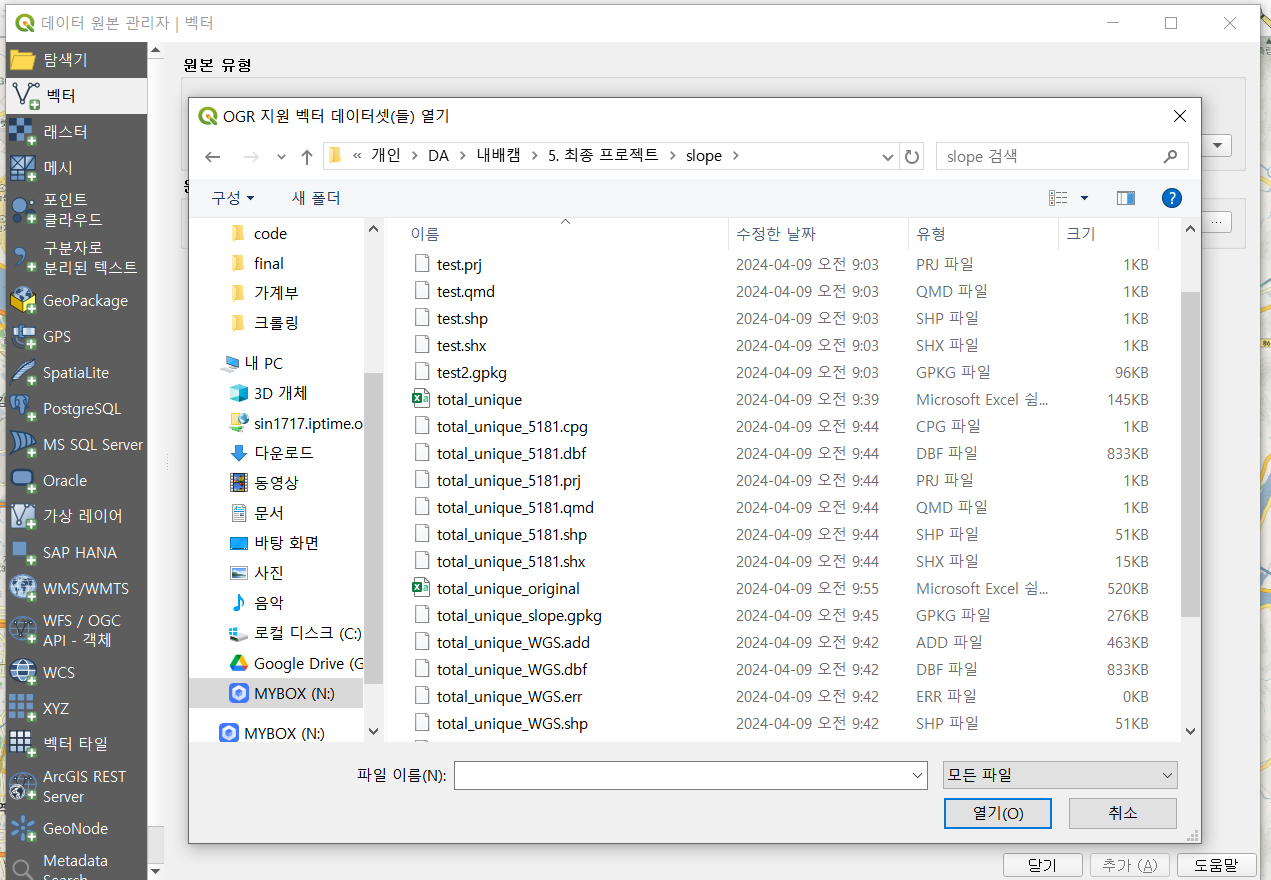
shp파일 생성이 완료되면 해당 shp파일을 QGIS상에서 열어줍니다.
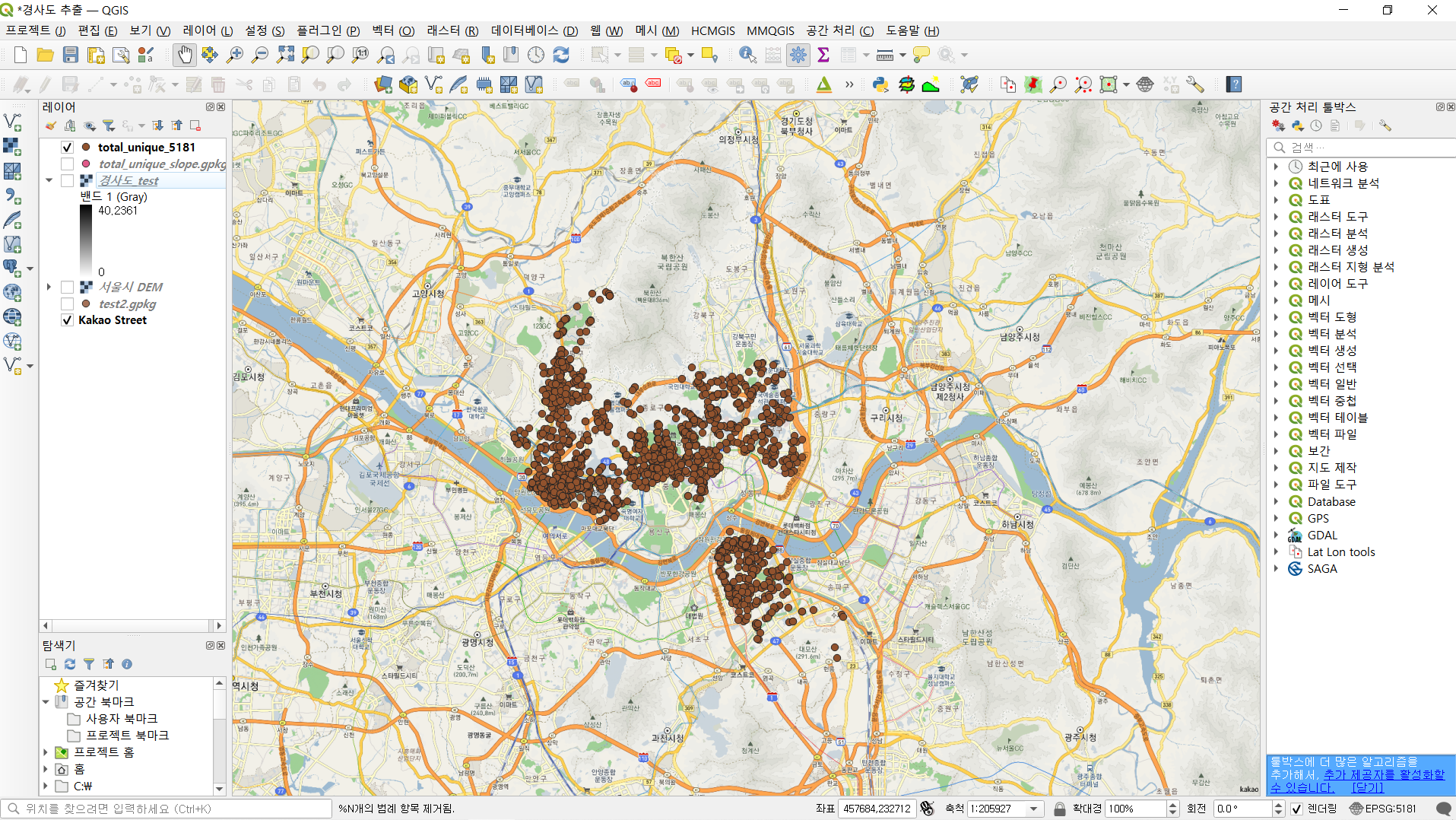
그러면 우측 이미지에서와같이 지도상에 해당 가게들이 위치한 모습을 확인할 수 있습니다.
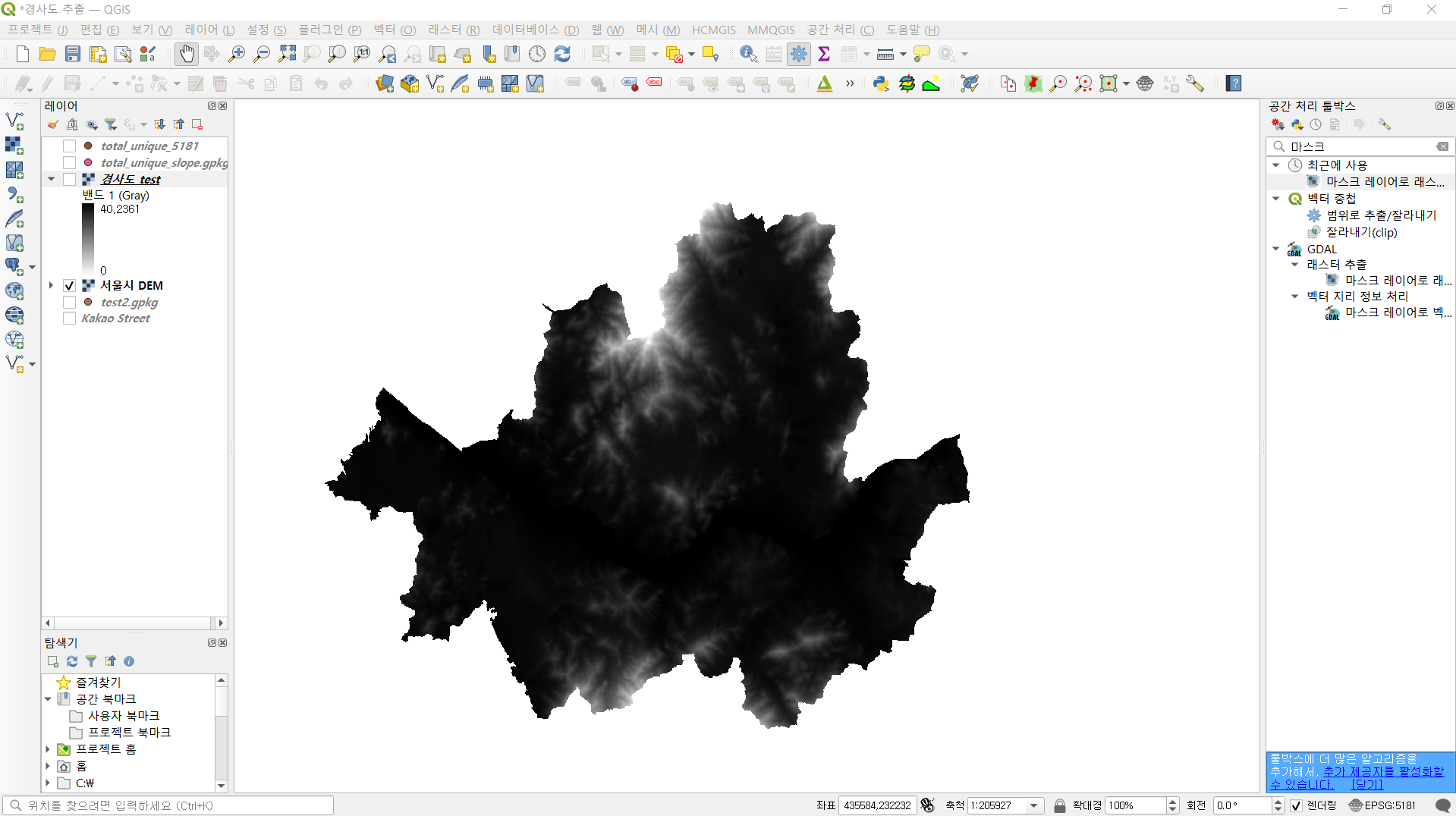
경사도를 구하기 위해서는 앞서 언급했던 DEM 지도가 필요한데
서울시의 DEM지도만 있으면 되기 때문에 전체 DEM지도에서
서울 전도 부분만큼만 잘라내어 사용했습니다.
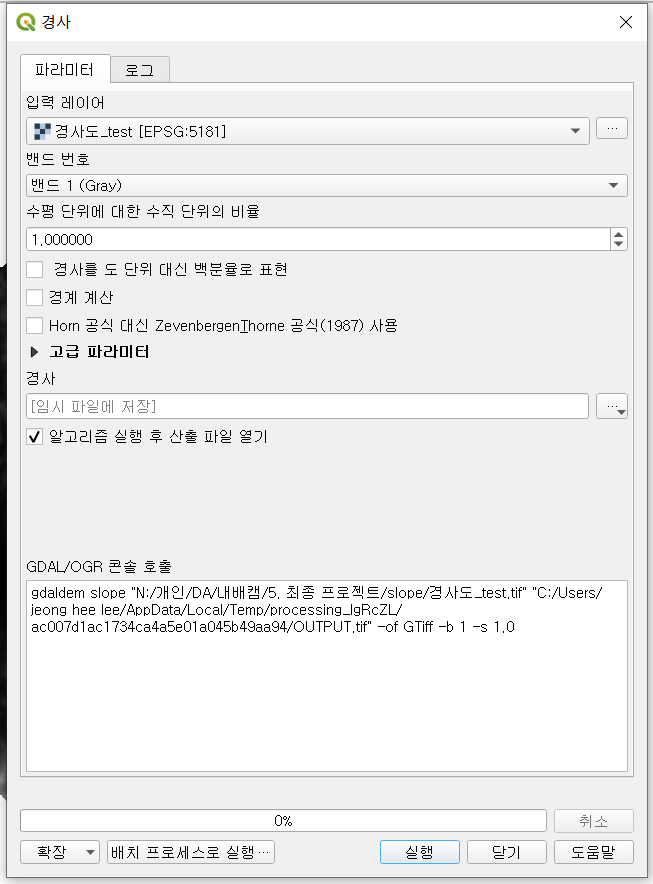
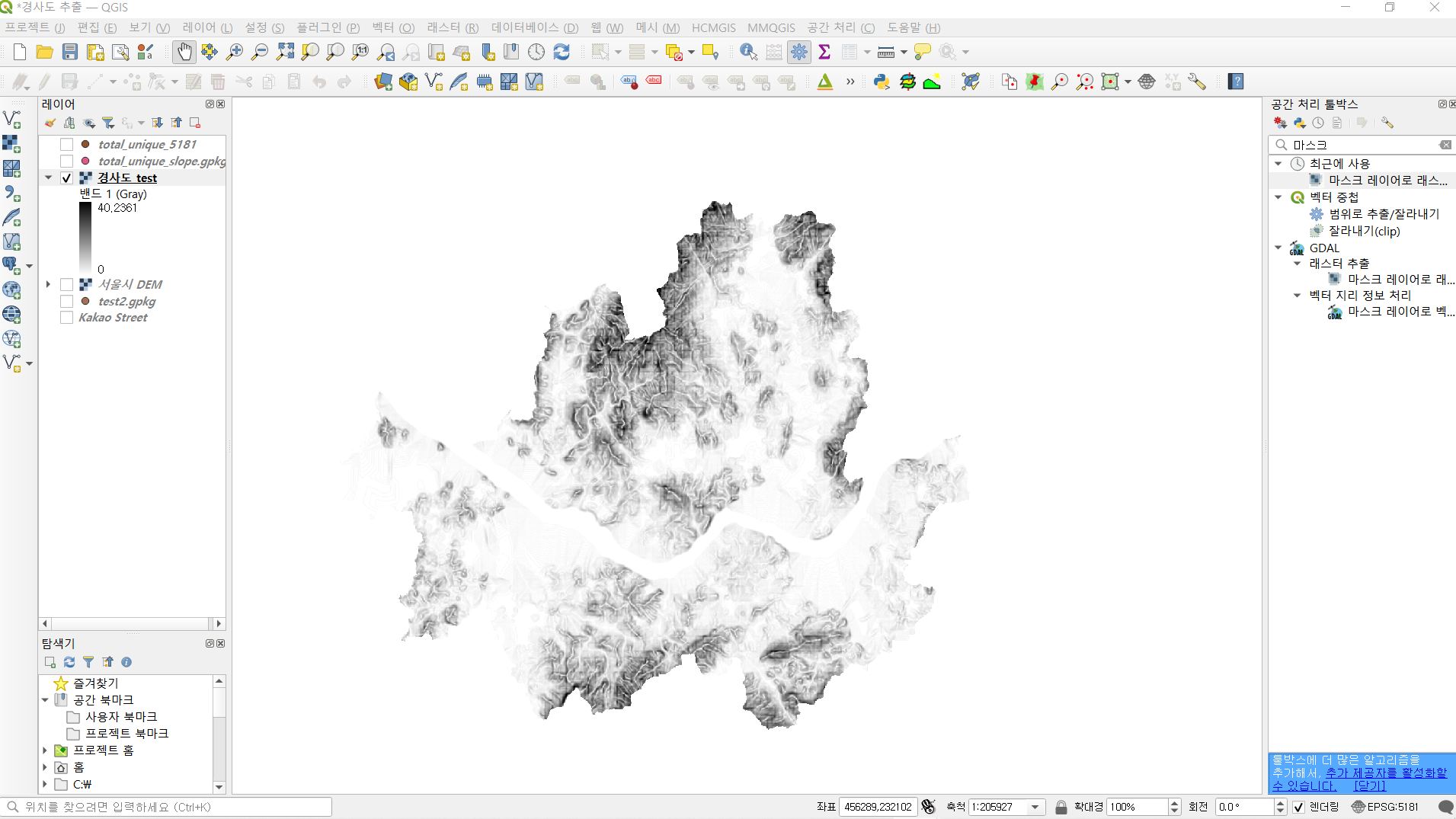
그리고나서 서울 DEM 지도를 가지고서 경사도를 측정했습니다.
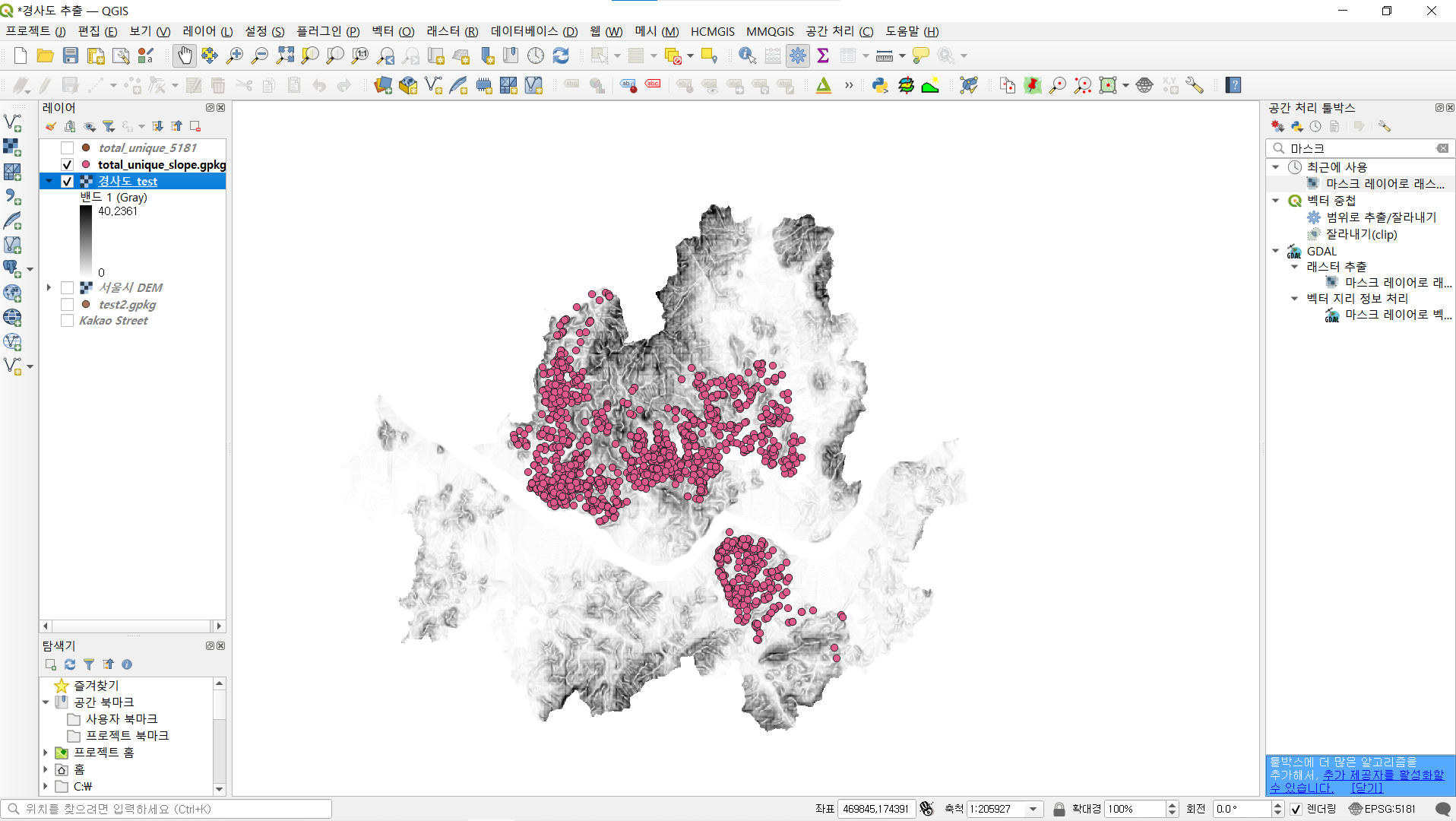
그 다음 앞단에서 준비한 경사도 자료와 가게 데이터를 가지고서 주소지별 경사도를 추출했습니다.
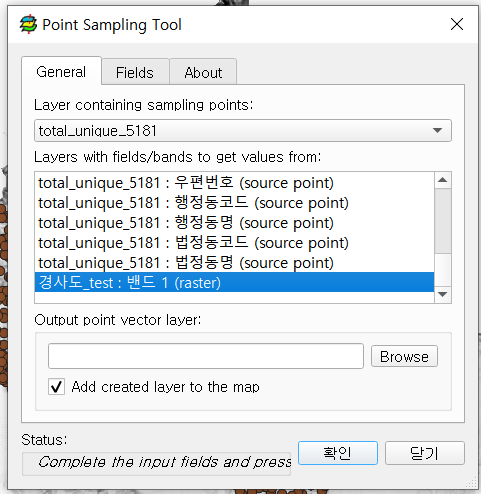
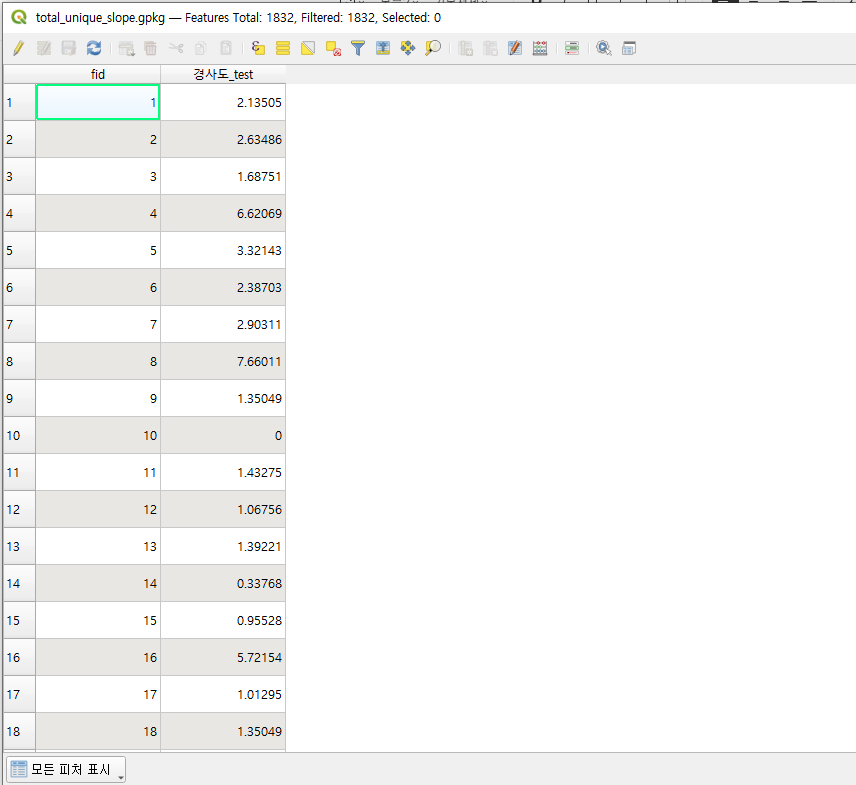
주소지별 경사도 추출 작업을 진행할 때는 Point Sampling Tool이라는 QGIS 플러그인을 활용했습니다.
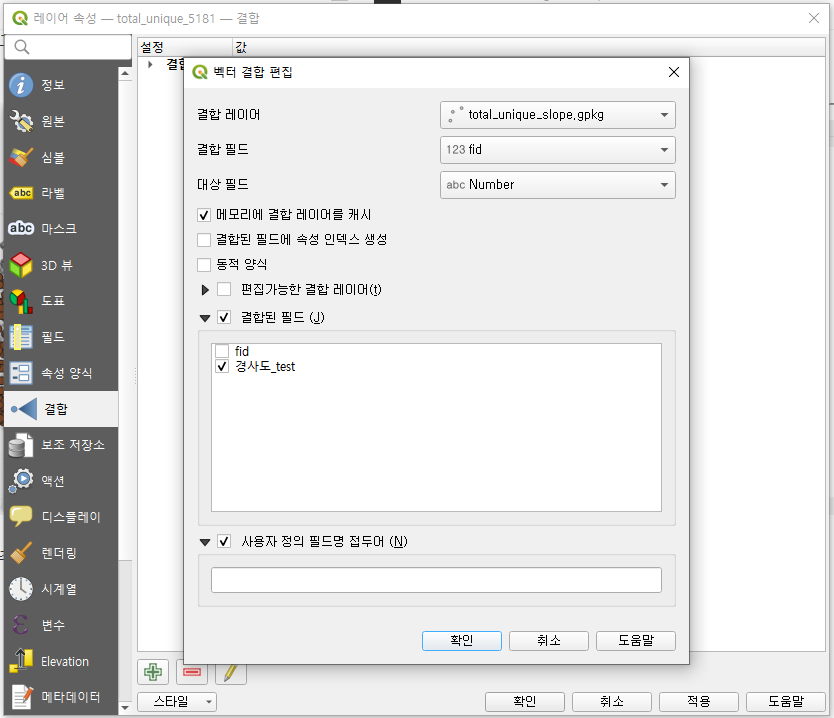
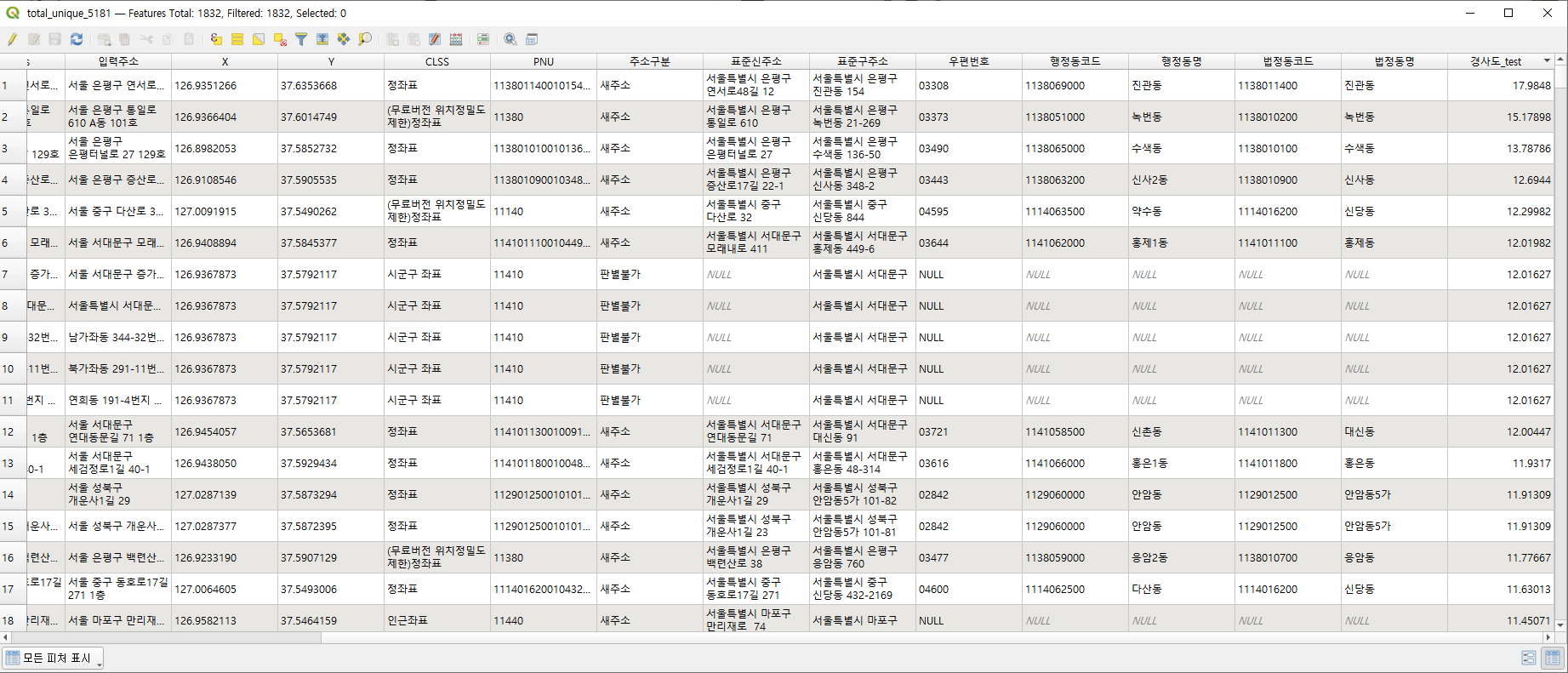
마지막 단계로 경사도 파일과 가게 데이터를 결합하여 가게 데이터에 '경사도' 컬럼을 추가했습니다.
# 파일 불러오기
total = pd.read_csv('N:/개인/DA/내배캠/5. 최종 프로젝트/after_cleansing/통합본/total.csv', index_col=0)
slope = pd.read_csv('N:/개인/DA/내배캠/5. 최종 프로젝트/slope/final/total_unique_slope_ver2.csv', encoding='cp949')
# merge
total_with_slope = pd.merge(total, slope, on='Store', how='left')이렇게 완성된 데이터를 csv파일로 내보내고 python에서 불러와
기존에 있던 통합 데이터셋과 merge시켰습니다.
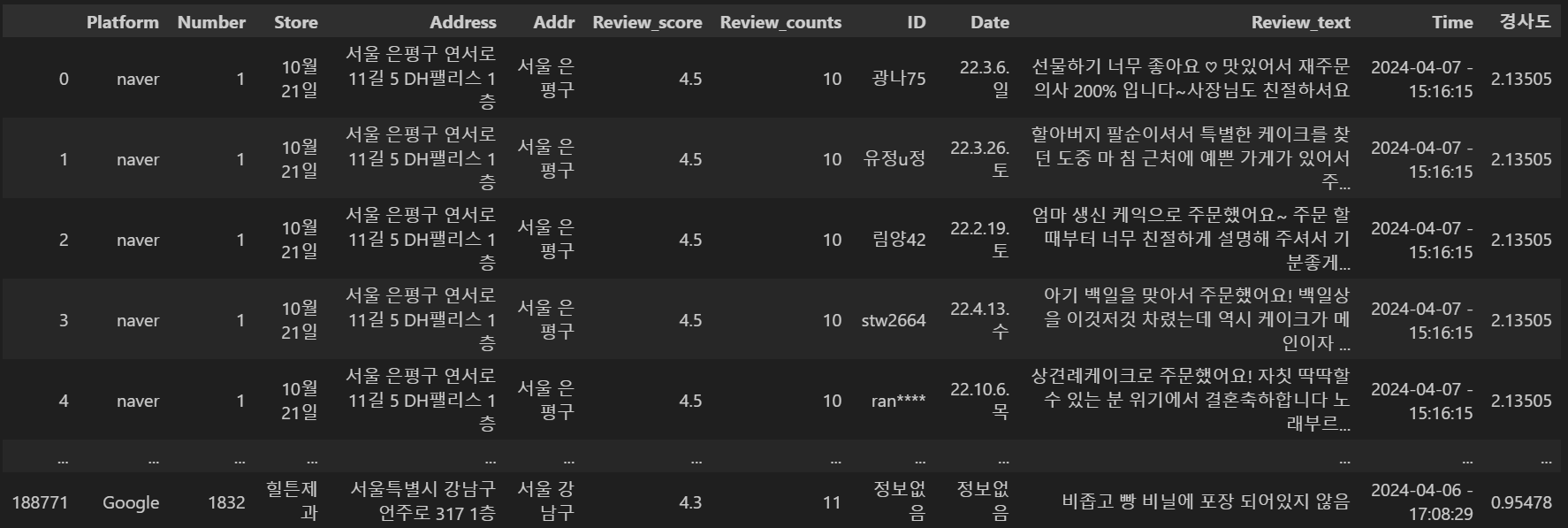
4. GPT API 코드 작성
오후 3시 30분에는 긍/부정 지수 및 특성 점수 부여를 위한 팀 회의가 있었습니다.
저희 팀은 긍/부정 지수 및 특성 점수 부여 時 인공지능 API를 활용할 예정이었기에
팀 회의 전 API 활용 코드를 작성했습니다.
감사하게도 튜터님 한 분이 Chat GPT API 활용 코드를 제공해주셔서
큰 틀에 세부적인 부분들만 수정/추가하였습니다.
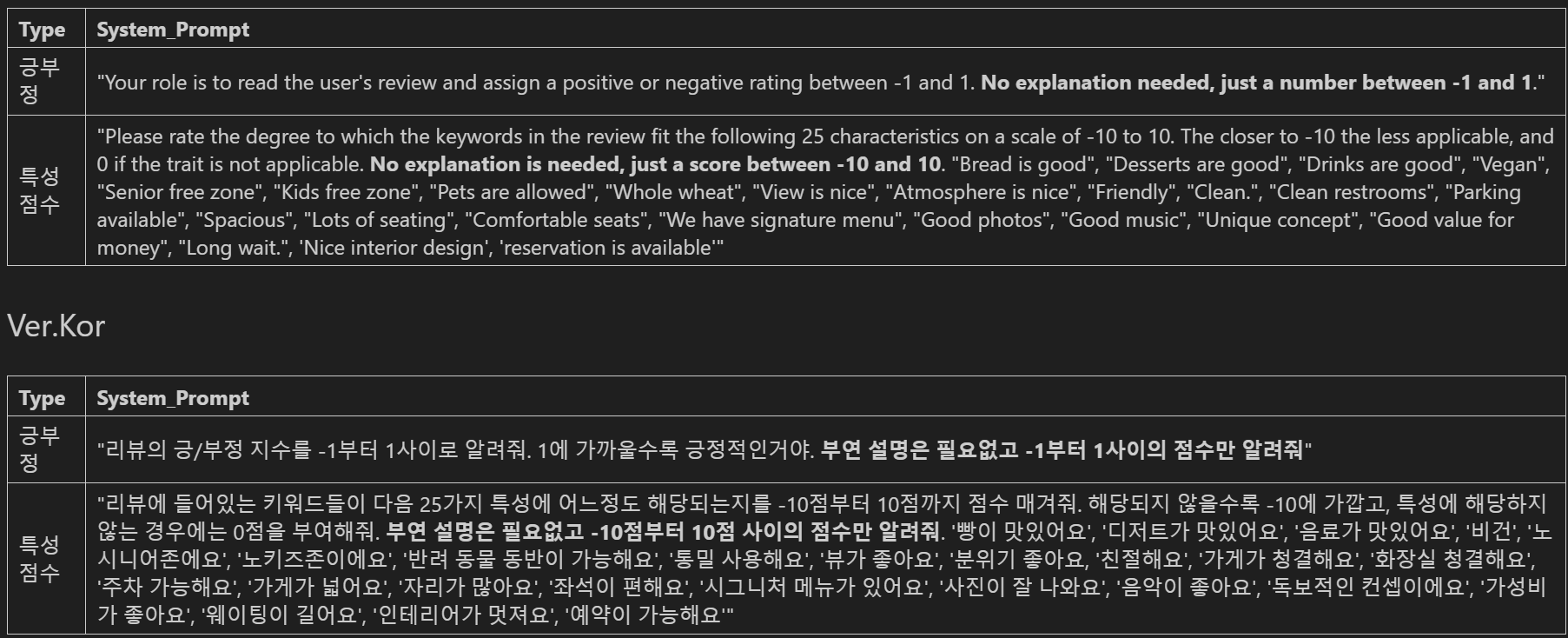
우선 저희가 사용할 프롬프트를 영어 버전과 국어 버전으로 정리해두었습니다.
# 긍/부정 지수 계산
def response_gpt(prompt):
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt}])
return response.choices[0].message.content
positivity_index = []
for i in df['Review_text']:
positivity_index.append(response_gpt(i))
df['positivity_index'] = positivity_index긍/부정 지수와 특성 점수를 계산하는 코드가 상이해서
별도로 코드를 작성했는데요,
먼저 긍/부정 지수를 계산하는 코드의 경우
각각의 리뷰마다 긍/부정 지수를 계산한 후 positivity_index라는 이름의 리스트에 넣어주었습니다.
그렇게 하면 리스트에 모든 리뷰의 긍/부정 지수들이 담겨있을 것이기때문에
해당 리스트를 가지고서 기존 통합 데이터셋에 긍/부정 지수 컬럼을 별도로 만들어 주려고했습니다.
# 특성 점수 계산
def response_gpt(prompt):
response = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
response_format={ "type": "json_object" },
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt}])
return response.choices[0].message.content
json_list = []
json_list.append(response_gpt(i))
df_list = [pd.DataFrame.from_dict(i, orient='index').transpose() for i in json_list]
merged_df = pd.concat(df_list, ignore_index=True)
merged_df.to_csv('feature_df.csv', encoding = 'utf-8-sig')특성 점수 계산의 경우 함수를 활용해서 특성별 점수를 계산한 후
딕셔너리 형태의 값들(특성 : 점수 / ex. '빵이 맛있어요' : 0.8)을 리스트에 넣어줍니다.
그런 다음 딕셔너리가 들어있는 리스트를 데이터프레임으로 변환해준 후 행 열을 전환해줍니다.
* 키워드별 특성이 행으로 가도록 초기값이 설정되어있기때문입니다.
그러면 각각의 딕셔너리가 하나의 데이터프레임이 되므로
각각의 데이터 프레임을 하나의 데이터프레임으로 concat해줍니다.
그렇게 완성된 데이터셋을 기존 통합 데이터셋에 합쳐주게됩니다.
5. GPT 프롬프트 고민
팀 회의가 시작된 후에는 팀원들과 함께 GPT 프롬프트를 작성했습니다.
우리가 어떻게 프롬프트를 작성하느냐에따라서 특성별 점수와 긍/부정 점수가 달라지기때문에
프롬프트 작성에 굉장히 많은 노력을 할애 할 수밖에 없었습니다.

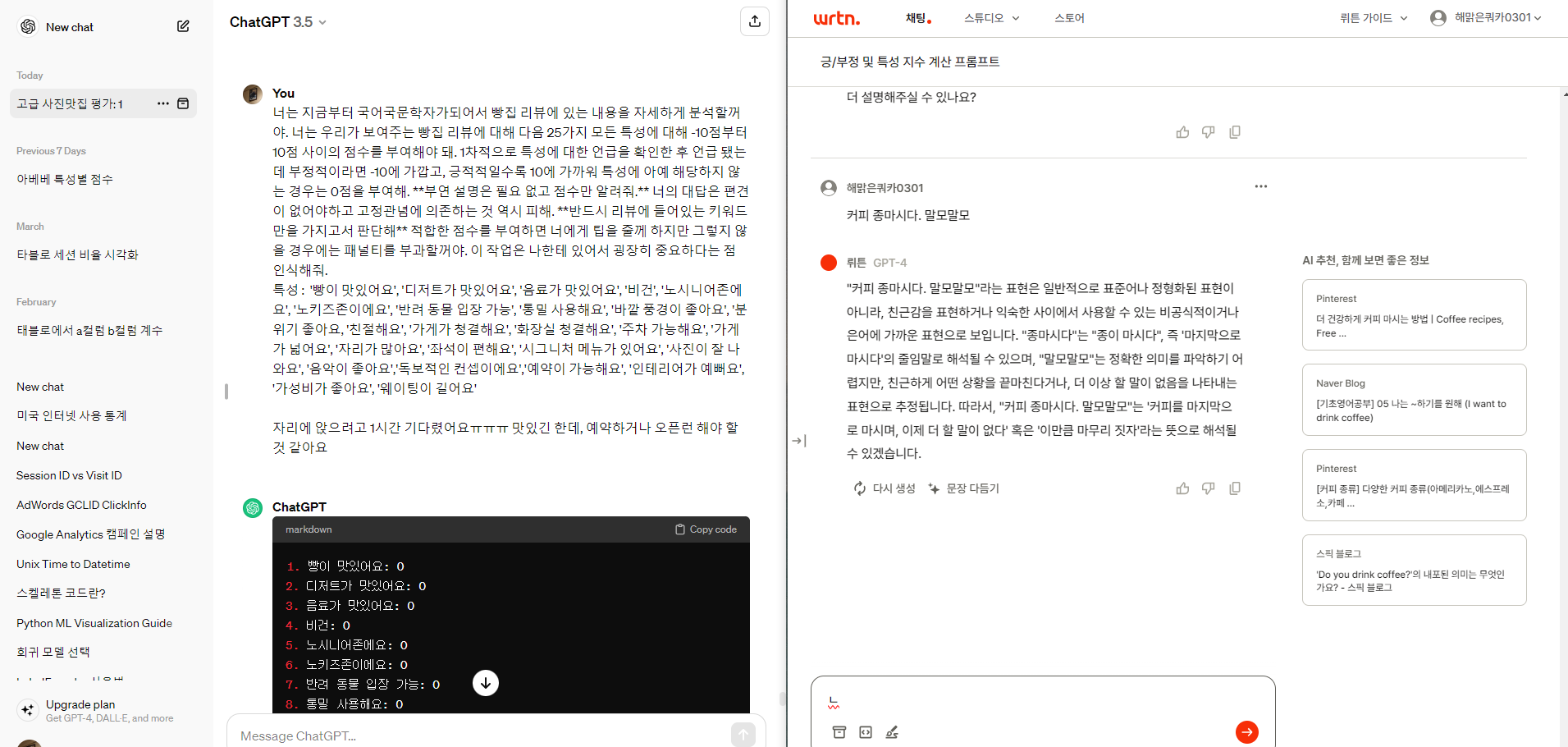
이런식으로 프롬프트를 수정해가면서 GPT가 우리가 원하는 수준의 답변을 하는지를 체크했습니다.
3시간 30분 정도 작업했는데 확실히 처음보다 답변의 수준이 많이 올라갔음을 느꼈습니다.
저녁 시간에는 튜터님께 저희가 작성한 프롬프트를 가지고서 튜터링을 받았는데
GPT API에 'temperature'라는 하이퍼 파라미터가 있는데
0부터 2 사이에 존재하는 이 파라미터는 0에 가까울수록 주어진 프롬프트를 기반으로 판단합니다.
그래서 내일은 이 temperature라는 하이퍼 파라미터를 튜닝하면서
답변의 퀄리티를 체크해볼 예정이고,
추가적으로 혹시나 GPT 4를 써야할 경우를 대비해(과금 폭탄)
2십만건 정도의 데이터를 최대 1십만건까지 줄이는 작업을 진행하려고합니다.
데이터 삭제 우선순위는 아래와 같습니다.

'데이터 분석 공부 > 프로젝트' 카테고리의 다른 글
| 최종 프로젝트 17일차(24.04.12) (0) | 2024.04.12 |
|---|---|
| 최종 프로젝트 15~16일차(24.04.10~11) (0) | 2024.04.11 |
| 최종 프로젝트 13일차(24.04.08) (0) | 2024.04.08 |
| 최종 프로젝트 11일~12일차(24.04.06~07) (1) | 2024.04.07 |
| 최종 프로젝트 10일차(24.04.05) (0) | 2024.04.05 |



