
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 서브쿼리
- SQL
- 데이터분석
- 태블로
- 팀프로젝트
- SQLD
- 시각화
- 프롬프트 엔지니어링
- If
- GA4
- Chat GPT
- data analyst
- Python
- 크롤링
- lambda
- cross join
- da
- 머신러닝
- 프로젝트
- jd
- 최종 프로젝트
- 기초프로젝트
- 전처리
- streamlit
- 기초통계
- 클러스터링
- pandas
- 군집화
- 데이터 분석
- 히트맵
- Today
- Total
세조목
Python 정리(데이터 전처리)(indexing, 컬럼 관련, 데이터 확인(info, describe, isna, notna, fillna, dtype), astype, 데이터 병합(merge, concat, join), groupby, 피벗, sort_values)(24.01.24) 본문
Python 정리(데이터 전처리)(indexing, 컬럼 관련, 데이터 확인(info, describe, isna, notna, fillna, dtype), astype, 데이터 병합(merge, concat, join), groupby, 피벗, sort_values)(24.01.24)
세조목 2024. 1. 24. 22:431. 인덱스
1) 인덱스 제거 방법 1 - 데이터 저장 時
data.to_csv("tips_data.csv", index=False)
2) 인덱스 제거 방법 2 - 데이터 불러올 時
df = pd.read_csv("tips_data.csv", index_col=0)
3) 인덱스 설정
df = pd.DataFrame({'A': [1,2,3], 'B' : ['a','b','c']}, index = ['idx3', 'idx2', 'idx1'])
2. DataFrame 만들기
data = {'name' : ['Alice', 'Bob', 'Charlie'],
'age' : [25,30, 35],
'gender' : ['female', 'male', 'male']
}
df = pd.DataFrame(data)
3. 컬럼 관련
1) 컬럼 조회
df.columns
2) 전체 컬럼명 변경
df.columns = ['이름', '나이', '성별']
3) 특정 컬럼명만 변경
# 첫번째 방법
df = df.rename(columns = {'name' : '이름'})
df = df.rename(columns = {'age' : '나이', 'gender' : '성별'})# 두번째 방법
데이터프레임명.columns.컬럼명[순서] = '새로운 컬럼명'
ex) outer.columns.values[2] = 'val2'
4) 컬럼 추가하기
df['스포츠'] = ['축구', '야구', '배구']
5) 컬럼 지우기
# 방법1
del df['스포츠']
# 방법2
데이터프레임명.drop('컬럼명', axis=1)
4. 데이터 확인 관련
1) 데이터 정보 확인
df.info()
2) 데이터 집계치 요약
df.describe()
3) 결측치 확인
● isna()
df.isna()df['B'].isna()특정 컬럼의 결측치만 True or False로 확인할 수 있고,
df[df['B'].isna()]특정 컬럼의 결측치 여부 확인 결과를 인덱싱해서
True인(=결측치가 있는)경우만을 모두 출력할 수도 있다.
뿐만 아니라 결측치가 있는 컬럼에서 결측치를 가지는 속성값이 몇 개인지를
확인하고자 할 때 확인하고자하는 컬럼의 결측치 정보를 변수에 넣어서
테이블의 모든 값들 중 그 값이 참인 값들만 추려내는 방식을 사용할 수도 있다.
코드는 아래와 같으며
cond = (titanic_df['Age'].isna())
titanic_df[cond].info()
결과값은 아래와 같이 출력된다.

● notna()
isna가 결측치를 확인하는 함수라면
notna는 결측치를 제외한 나머지 값들을 확인하는 함수다.
확인하고자하는 컬럼뒤에 '.notna()'를 붙여주기만 하면 된다.
titanic_df['Age'].notna()
4) 데이터 타입 확인
df['total_bill'].dtype
df['tip'].dtype
5) 데이터 타입 변경
df['total_bill'] = df['total_bill'].astype(str)실수(float) 형태의 문자는 바로 int로 바꿀 수 없는데
float으로 바꾸고, int로 바꾸면 변경된다.
df['total_bill'] = df['total_bill'].astype(float).astype(int)
6) 결측치 채워넣기
fillna 함수를 사용하여 결측치를 채워넣을 수 있다.
fillna( ) 소괄호 안에 넣고자하는 값을 넣으면 된다.
titanic_df['Age'].fillna(25)
5. 인덱싱
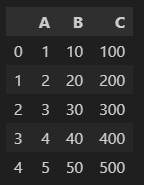
iloc과 loc의 차이점
2024.03.11 - [데이터 분석 공부/Python] - Python - shape속성 & loc와 iloc의 차이
1) iloc
df.iloc[0,0:3]행과 열을 콤마(,)로 구분할 수 있다.
[0, 0:3]이 의미하는 것은
0번째 행,
0~2번째 컬럼
이다.
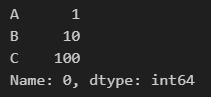
0번째 행, 0~2번째 컬럼의 값인
1, 10, 100이 출력되는 것을 확인할 수 있다.
2) loc

df.iloc[:,0]모든 행, 0번째 컬럼 출력
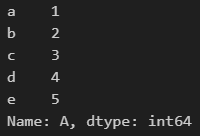
df.loc[:,'A']모든행, 'A' 컬럼 출력
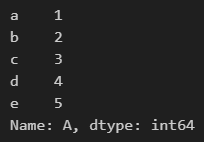
df.loc['b':'d','A':'B']b부터 d까지의 행,
A부터 B까지의 컬럼 출력

두 개 이상의 컬럼 불러오기
df[['A','B']]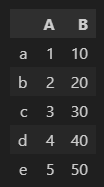
df[['B', 'A']]
두 개 이상의 행, 컬럼 불러오기
df.loc['a':'b',['A', 'C']]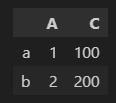
df.loc['a':'b','B':'C']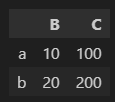
6. boolean indexing
# df 테이블에서 'sex'가 'Male'인 '참'인 경우만 인덱싱함
df[df['sex']=='Male'].head(5)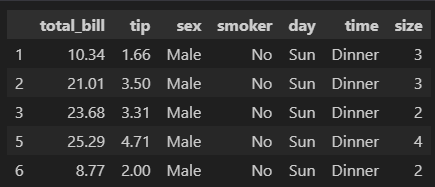
# and 조건
df[(df['sex']=='Male') & (df['smoker'] =='Yes')]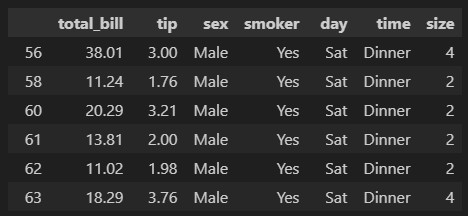
# or 조건
df[(df['sex']=='Male') | (df['smoker']=='Yes')].head()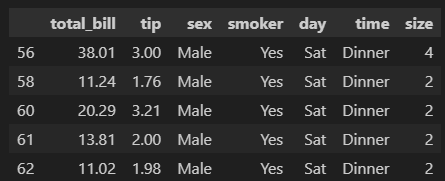
# 'size'컬럼의 값이 3을 초과하는 경우에 해당하는 행, 'tip'부터 'day' 컬럼을 출력
df.loc[df['size']>3,'tip':'day'].head()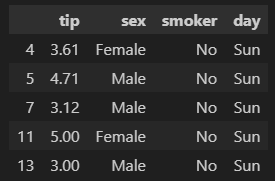
# 특정 컬럼에서 특정 값만 골라서 보고싶을때
df[df['size'].isin([1,2])].head()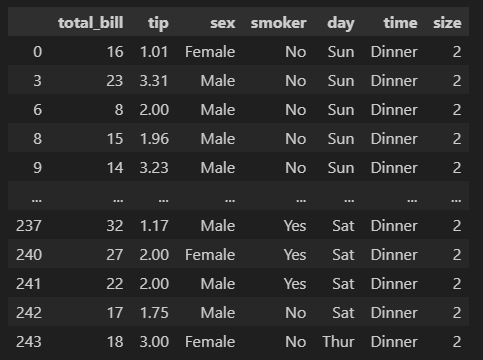
df[df['day'].isin(['Sun', 'Thur'])]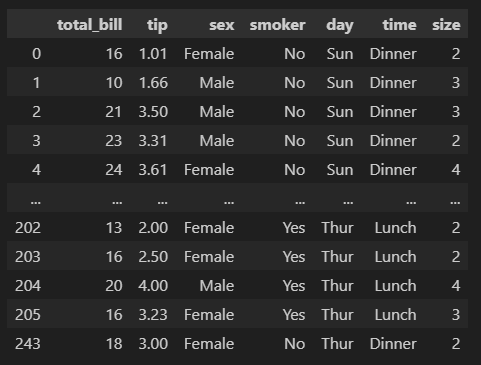
7. Boolean(True or False) 확인 방법
df['day'] == 'Sun'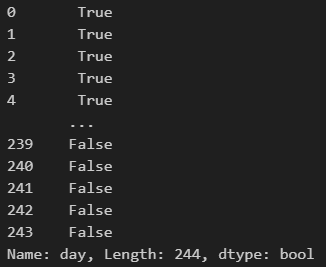
df['tip'] < 2
# 특정 조건에 해당하는 값들을 변수로 지정하고,
# 그 변수를 인덱싱하면 그 값들의 True or False 여부 확인 가능
condition = df['tip'] < 2
condition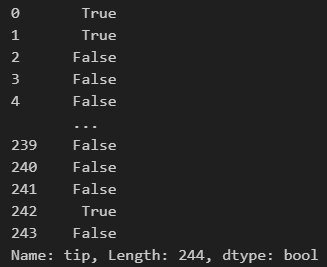
# 인덱싱하면 'tip' 컬럼이 2보다 작은 경우에 해당하는 모든 값들이 출력됨
df[condition].head()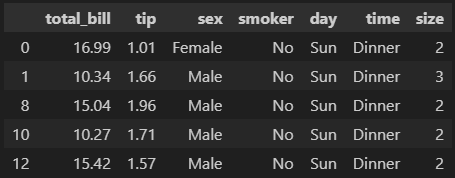
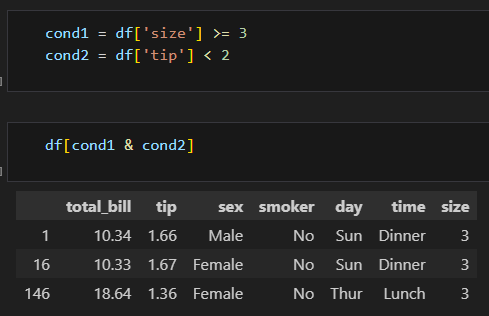
이런 식으로 특정 조건을 변수에 넣어서
그 변수를 가지고서 인덱싱 할수도 있음
cond = (df['sex'] == 'Male') \
& (df['tip'] > 3) \
& (df['smoker'] == 'Yes') \
& (df['total_bill'] >= 20) \
& (df['size'] == 4)
df[cond]
# 줄바꿈 기호(\)가 없으면 'unexpected index' 오류가 뜸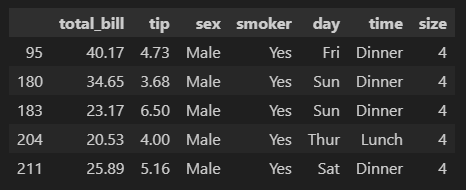
이렇게 여러 조건을 줄수도 있음
8. 데이터 추가하기
df['created_at'] = '2024-01-01'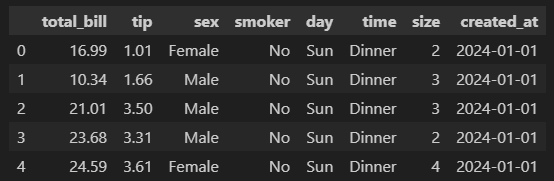
9. 날짜로 바꾸기
pd.to_datetime(df['created_at'])데이터프레임 df의 'created_at' 컬럼을 날짜 형태로 변경하겠다는 코드
df['created_at'] 뒤에
format = '%Y-%d'
를 입력해줌으로써 날짜의 형식을 지정할 수 있는데
%뒤에 대·소문자 Y, M, D가 들어간다.
10. 데이터 병합
1) concat
# axis는 기본값(위아래 / axis=0)으로 지정되어있음
pd.concat([df1,df2,df3], axis=0).reset_index(drop=True)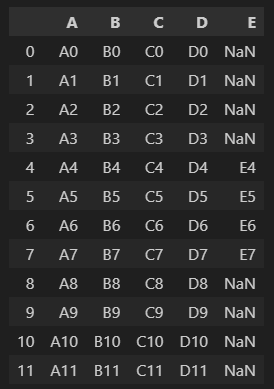
.reset_index(drop=True)를 적어주지 않으면 df2, df3의 인덱스가 각각 0부터 시작됨
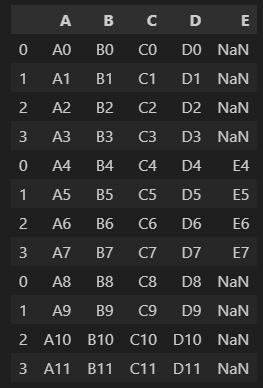
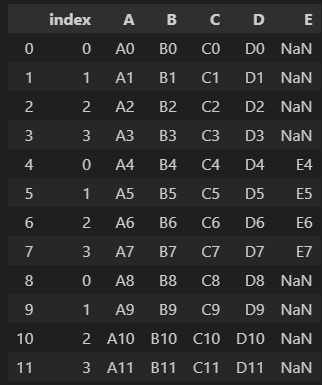
drop=False를 하면 index 컬럼이 생기는데 True로 적으면 index컬럼이 사라진다.
# axis=1로 하면 좌우로 붙일 수 있음
# 행과 열이 동일하지 않다면 없는 부분에는 NULL이 표시됨
df = pd.concat([df1,df2], axis=1)
2) merge
# concat이 데이터프레임을 좌우, 상하로 붙여주는거라면 merge는 특정 컬럼을 고려해서 병합해줌
# SQL의 JOIN과 동일한 기능
# 'how'의 기본값은 'inner'로 'outer'로 변경하면 합집합됨
pd.merge(df1, df2, on='key', how='inner')
outer = pd.merge(df1, df2, on='key', how='outer')concat 메서드에서는 [ ]안에 각각의 데이터프레임을 넣어줬지만
merge 메서드에서는 각각의 데이터프레임을 리스트 안에 넣어줄 필요가 없다.
# left, right join도 가능함
pd.merge(df1, df2, on = 'key', how='left')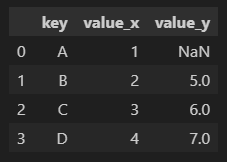
left join은 왼쪽 데이터프레임에 있는 값들은 모두 출력한다.
pd.merge(df1, df2, on = 'key', how='right')
right join은 오른쪽 데이터프레임에 있는 값들은 모두 출력한다.
pd.merge(df3, df4, left_on = 'id', right_on = 'user_id')
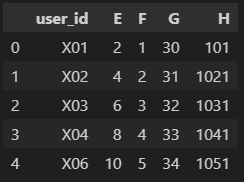
기준이 되는 컬럼의 이름이 다를수도 있다.
이 때는 left_on과 right_on에 기준이 되는 컬럼명을 각각 적어줘야한다.
위 예시의 경우 두 데이터프레임 모두 기준이 되는 컬럼이 'id'와 'user_id'이긴하나
컬럼명이 다르기때문에
left_on에는 'id'를 right_on에는 'user_id'를 적어준다.
3) join
df5.join(df6)
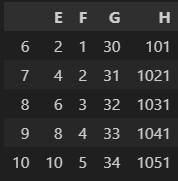
위 데이터프레임이 df5, 아래 데이터프레임이 df6다.
두 데이터프레임을 붙일때 concat, merge 뿐만 아니라 join을 쓸수도 있다.
유의해야할 점은 join의 경우 기본적으로 인덱스를 기준으로하여 left join하기때문에
join방식을 바꾸고싶다면 'how'를 적어줘야한다.
df5.join(df6, how='right')이렇게 코드를 작성하면 df5와 df6가 인덱스를 기준으로 right join된다.
11. groupby
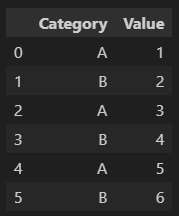
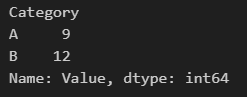
df.groupby('Category').sum()
df.groupby('Category')['Value'].sum()'Category'를 기준으로 sum하겠다.
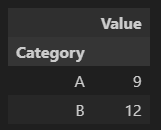
'Category'를 기준으로 'Value' 컬럼에 있는 값들을 sum하겠다.
# 처음 값만 출력
df.groupby('Category').first()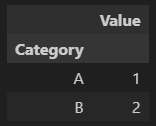
df.groupby('Category').agg(list)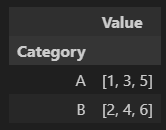
'Category'를 기준으로 Value 컬럼의 값들을 리스트화한다.
# ( )에는 기준이 되는 컬럼명이 들어가고 [ ] 에는 집계하고자하는 컬럼들이 들어감
# 첫번째 방법
df[['sex', 'day', 'total_bill', 'tip', 'size']].groupby(['sex', 'day']).mean()# 두번째 방법
df.groupby(['sex', 'day'])[['total_bill', 'tip', 'size']].mean()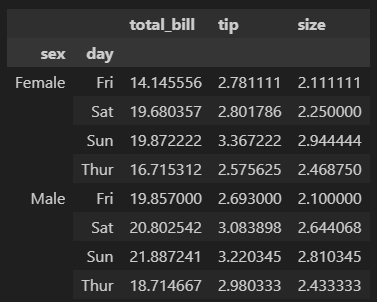
'sex'와 'day' 컬럼이 기준이 되기때문에
groupby.( ) 안에 리스트로 묶어서 넣어주고
집계하고자하는 컬럼인 'sex', 'day', 'total_bill', 'tip', 'size'는 [ ]안에 넣어줌
대괄호([ ]) 안에는 집계하고자하는 컬럼을,
소괄호(( )) 안에는 기준이 되는 컬럼을
넣어준다.
첫번째 방법으로 입력할 때에는 대괄호([ ])안에 기준이 되는 컬럼들('sex', 'day')도 모두 적어준다.
# 컬럼별로 집계를 다르게 지정할 수 있음
df[['sex', 'day', 'total_bill', 'tip', 'size']].groupby(['sex', 'day']).agg({'total_bill' : 'max', 'tip' : 'mean', 'size' : 'sum'})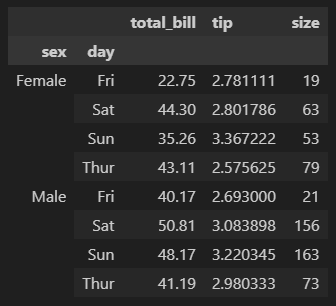
컬럼별로 집계를 다르게 할 수 있다.
total_bill 컬럼은 max를
tip 컬럼은 mean을
size 컬럼은 sum을
구하고있다.
12. 피벗테이블
# 기본 구조
pivot = df.pivot_table(index='Date', columns = 'Category', values='Value', aggfunc='sum')# 컬럼을 두 개 이상 지정할 수 있음
pivot2 = df2.pivot_table(index='Date', columns = ['Category', 'SubCategory'], values = 'Value', aggfunc='sum')
13. 데이터 정렬
# 기본 구조
df3.sort_values(by='Age', ascending=False)
# 정렬 기준도 여러 가지 지정할 수 있음
df3.sort_values(by=['Age', 'Score'], ascending=[True, False])
# 인덱스 기준으로도 정렬할 수 있음
df.sort_index(ascending=False)'데이터 분석 공부 > Python' 카테고리의 다른 글
| Python 정리(데이터 시각화)(24.01.25) (1) | 2024.01.25 |
|---|---|
| Python 정리(새로운 컬럼 만들기 = assign, 날짜 타입으로 변경 = pd.to_datetime, 요일을 숫자로 추출 = dt.weekday)(24.01.25) (1) | 2024.01.25 |
| VSCode 폰트 크기 마우스 휠로 조절하는 방법 (0) | 2024.01.24 |
| PYTHON 정리(프로그래머스 - '행렬의 덧셈')(24.01.21) (1) | 2024.01.21 |
| PYTHON 정리(append, insert 차이)(24.01.21) (0) | 2024.01.21 |



