
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 최종 프로젝트
- SQLD
- data analyst
- 프롬프트 엔지니어링
- 클러스터링
- 군집화
- jd
- SQL
- 데이터분석
- 전처리
- Python
- 팀프로젝트
- Chat GPT
- 기초통계
- 기초프로젝트
- If
- 태블로
- streamlit
- da
- 프로젝트
- pandas
- GA4
- cross join
- 크롤링
- 히트맵
- 데이터 분석
- 시각화
- lambda
- 머신러닝
- 서브쿼리
- Today
- Total
세조목
Python 정리(데이터 시각화)(24.01.25) 본문



1. 차트 개괄
df = pd.DataFrame({
'A' : [1,2,3,4,5],
'B' : [5,4,3,2,1]
})
df.plot(x='A', y='B')위와 같이 만든 데이터프레임이 있을때
x축과 y축에 각각의 컬럼 이름을 넣어주면 간단하게 그래프를 그릴 수 있다.
data_grouped = data.groupby('year')[['year', 'passengers']].sum()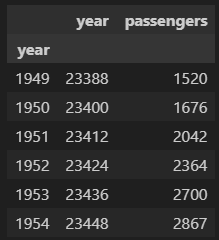
위와 같은 데이터 프레임을 그래프로 나타낼때는
plt.plot(data_grouped['year'], data_grouped['passengers'])plt.plot( )안에 세로축에 넣을 컬럼, 가로축에 넣을 컬럼을
순서대로 넣어주는 식으로도 차트를 그릴 수 있다.
x = [1,2,3,4,5]
y = [2,4,6,8,10]
plt.plot(x,y)데이터프레임이 아닌 리스트가 담긴 변수일 경우
plt.plot( ) 안에 변수만 넣어주면 그래프가 그려진다.
df.plot(x='A', y='B', color = 'red', linestyle = '--', marker = 'o', label='Data Series')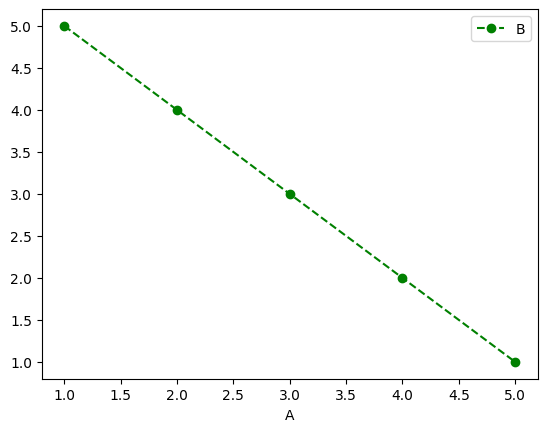
색깔, 선 스타일, 마커, 범례도 지정해줄 수 있다.
참고로 범례는
'label = 'Data Series' 뿐만 아니라
'테이블명.legend(['Data Series'])' 를 통해서도
나타낼 수 있다.
ax = df.plot(x='A', y='B', color = 'red', linestyle = '--', marker = 'o')
ax.legend(['Data Series'])
ax.set_xlabel('X-axis')
ax.set_ylabel('Y-axis')
ax.set_title('Title')
ax.text(2, 3, 'Some Text', fontsize=12)
ax.text(2, 2, 'Some Text 2', fontsize=10)변수.text( ) 를 입력함으로써 그래프 상에 텍스트를 추가해줄수도 있다.
2. 바 그래프와 히스토그램
plt.bar(df['도시'], df['인구'])
plt.xlabel('도시')
plt.ylabel('인구')
plt.title('도시별 인구 수')
plt.show()
바 그래프를 그릴때는 plt.bar( )안에 가로, 세로축에 들어갈 컬럼명을 입력해주면 된다.
plt.hist(data, bins=30)
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.title('히스토그램')
plt.show()
히스토그램은 plt.hist( ) 안에 '확인하고자하는 데이터'와 bins=' ' 를 넣어주면 된다.
여기서 bins는 몇 개의 구간을 두어서 표현할 것인지에 대한 값을 의미한다.
아래는 seaborn 라이브러리의 메서드를 활용하여 히스토그램을 구하는 코드 예시다.
sns.histplot(data = tips_df, x='total_bill', bins = 20)
matplotlib과 seaborn 라이브러리를 사용하지 않고서도 히스토그램을 그릴 수 있으며
코드는 아래와 같다.
tips_df['total_bill'].hist()
tips_df['total_bill'].plot.hist()

확실히 seaborn 라이브러리를 사용하는 것이
그래프 디자인이 가장 깔끔한 것을 확인할 수 있다.
3. 파이 차트
sizes = [30,20,25,15,10]
labels = ['A', 'B', 'C', 'D', 'E']
plt.pie(sizes, labels=labels)
plt.title('Pie Chart')
plt.show()
파이 차트는 plt.pie( ) 안에 x, y축에 들어갈 변수(또는 컬럼명)을 적어주면된다.
파이 차트를 만들때 수정할 수 있는 옵션들이 다양한데 하나씩 살펴보자
● 비율 표시
plt.pie( ) 안에 autopct를 적어주면 부채꼴 안에 숫자를 표시할 수 있다.
만약 '%.1f%%'를 입력하면 소수점 한자리까지 표시할 수 있다.
예시는 다음과 같다.
plt.pie(autopct = '%.1f%%')
● 중심에서 벗어나는 정도 설정
각각의 부채꼴들이 중심으로부터 어느정도 벗어나게끔 표시할 것인지를 지정할 수도 있다.
plt.pie( ) 안에 'explode = ' 를 적어주면 되는데
등호 표시 뒤에는 각 부채꼴들이 중심으로부터 어느정도 벗어나게끔 할 것인지를 나타내는 숫자를 적어준다.
예시는 아래와 같다.
plt.pie(explode = [0.5, 0.7, 0, 0.2])
이 때 유의할 점은 부채꼴의 개수만큼 숫자를 적어줘야한다는 점이다.
● 그림자 표현
부채꼴의 그림자를 표현할 수 있다.
plt.pie( ) 안에 'shadow=True'를 입력해주면 된다.
예시는 아래와 같다.
plt.pie(shadow=True)
● 색상 지정
각 부채꼴들의 색상을 지정할 수 있다.
별도의 변수에 부채꼴의 숫자만큼 색상을 적어주고(ex. colors = ['silver', 'yellow', 'red', 'orange', 'skyblue'])
plt.pie( ) 안에 colors = 뒤에 변수를 적어주면 된다(ex. colors = colors).
이 때 색상은 영문뿐 아니라 Hex code를 적어줘도 무방하다.
※ Hex code 예시 : #ff9999, #ffc000
예시는 아래와 같다.
plt.pie(colors = ['silver', 'yellow', 'red', 'orange', 'skyblue']) / plt.pie(colors = colors)
4. Box Plot
Box Plot은 데이터의 분포와 이상치를 시각적으로 보여주는 그래프다.
특정 카테고리의 범위나 이상치를 확인하고싶을때 활용할 수 있다.

위와같은 'iris'라는 이름의 DataFrame이 있다고 가정해보자.
species = iris['species'].unique()
species
>>> array(['setosa', 'versicolor', 'virginica'], dtype=object)iris테이블에서 species 컬럼만을 중복값 없이 출력해보면
위와 같이 리스트 형태로 출력된다.
sepal_lengths_list = [iris[iris['species'] == s]['sepal_length'].tolist() for s in species]
sepal_lengths_list
>>> [[5.1,
4.9,
4.7,
4.6,
5.0,
5.4,
4.6,
5.0,
4.4,그런 다음 for문을 활용해서 species 리스트에서 반복적으로 값을 뽑아내고,
iris 테이블의 species 컬럼의 값이 s인 값 中 'sepal_lengths' 컬럼의 값만을 출력한다.
그리고 그 값들을 리스트 형태로 불러오기위해 '.tolist( )' 메서드를 사용한다.
plt.boxplot(sepal_lengths_list, labels=species)
plt.xlabel('Species')
plt.ylabel('Sepal Length', rotation = 360, labelpad = 40)
plt.title('Box plot')
plt.show()
그 값들을 sepal_lengths_list라는 변수에 넣어주는데
이 변수를 가지고서 Box Plot을 그리면 위와 같다.
구조는 plt.boxplot(데이터, labels = ) 이다.
| 주황선 | 중앙값 |
| 주황선 아래 박스 | 전체 中 25%~중앙값 |
| 주황선 위 박스 | 전체 中 중앙값~75% |
| 실선과 가로선 | 최소, 최대값을 의미 |
| 점 | 아웃라이어(이상치) |
matplotlib 라이브러리 외에도
seaborn 라이브러리를 가지고서도 box plot을 그리볼 수 있다.
sns.boxplot(x='species', y='sepal_length', data = iris)
5. 산점도
plt.scatter(iris['petal_length'], iris['petal_width'])
plt.xlabel('Petal length')
plt.ylabel('Petal width', rotation=45, labelpad = 30)
plt.show()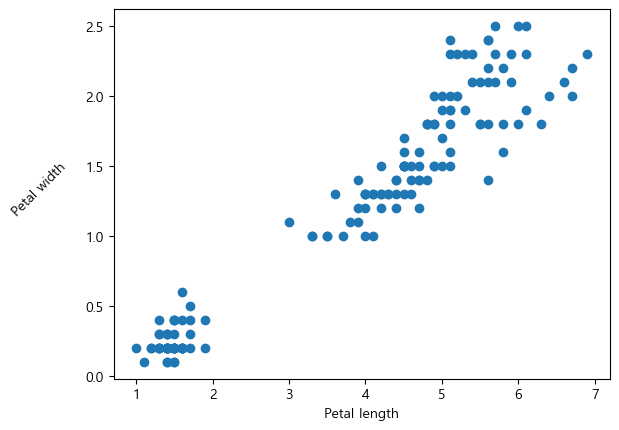
산점도는
plt.scatter(x축에 나타낼 컬럼, y축에 나타낼 컬럼)
을 입력함으로써 나타낼 수 있다.
만약 산점도와 라인 차트를 같이 나타내고 싶다면 어떤 코드를 적어야 할까?
산점도의 경우 앞에서 확인했던 것처럼
sns.scatterplot(data = tips_df, x='total_bill', y = 'tip)과 같이 입력해주면 되고,
그 밑에 바로 라인 차트를 나타내는 코드를 작성해주면 된다.
그렇게 했을때의 완성 코드는 아래와 같고
sns.scatterplot(data = tips_df, x='total_bill', y = 'tip)
sns.lineplot(data=tips_df, x='total_bill', y='pred', color = 'red')
결과 그래프는 아래와 같다.

참고로 위 그래프는 LinearRegression 함수를 활용한 선형회귀 그래프다.
6. pairplot
pairplot은 하나의 도화지에
여러 종류의 그래프를 한눈에 확인할 수 있는 그래프다.
sns.pairplot('테이블명')
코드는 위와 같이 굉장히 간단하고,
결과물은 아래와 같다.
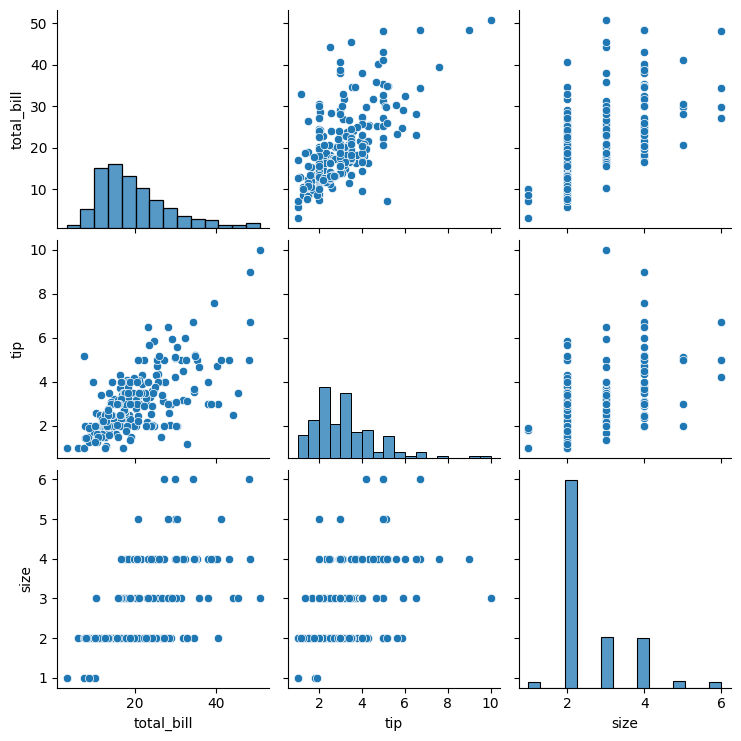
추가적으로 상관관계 관련하여
우리가 상관계수를 확인하고자 할 때는
corr함수를 사용하면 되는데
테이블에 문자가 포함되어있다면
'setosa' 오류가 발생할 것이다.
오류를 해결할 수 있는 방법은 총 두가지가 있는데
첫번째는 전처리를 해주는 것이고,
두번째는 corr( )안에 numeric_only=True 을 넣어주는 것이다.
corr('테이블명', numeric_only = True)위와같이 말이다.
전처리를 하겠다면
아래와 같이 문자가 포함되어있는 컬럼을
drop 함수를 사용하여 삭제하면 된다.
iris2 = iris.drop('species', axis=1) # axis=1은 컬럼을 제거한다는 의미
iris2.corr(method='pearson')


