
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 팀프로젝트
- jd
- Python
- 군집화
- SQLD
- 머신러닝
- pandas
- 기초프로젝트
- 데이터 분석
- 기초통계
- 프롬프트 엔지니어링
- SQL
- 데이터분석
- 시각화
- 서브쿼리
- da
- streamlit
- 히트맵
- 전처리
- 최종 프로젝트
- 프로젝트
- data analyst
- GA4
- If
- 크롤링
- 태블로
- lambda
- cross join
- Chat GPT
- 클러스터링
- Today
- Total
목록Python (224)
세조목
Python 금일은 머신러닝 개인과제를 수행했습니다. 과제를 수행하며 새롭게 학습한 함수들을 간략하게 정리했습니다. 2024.02.03 - [데이터 분석 공부/Python] - Python 정리(속성값 변경, 차원 확인, enumerate)(24.02.03) Python 정리(속성값 변경, 차원 확인, enumerate)(24.02.03) 속성값 변경 df['컬럼명'] = df['컬럼명'].replace('기존값', '수정값') ex) df['name'] = df['name'].replace('Joe', 'Kane') 차원 확인(shape) 변수명.shape 분리한 데이터셋의 차원을 볼 수 있음 차원이란 '데이터셋에 eyeoftheworld1209.tistory.com 시간 관계상 미처 정리하지 못한 부..
 Python 정리(replace, shape, enumerate)(24.02.03)
Python 정리(replace, shape, enumerate)(24.02.03)
속성값 변경 df['컬럼명'] = df['컬럼명'].replace('기존값', '수정값') ex) df['name'] = df['name'].replace('Joe', 'Kane') ※ 특정 열의 특정 값만 바꾸고자 할 때 df.replace({컬럼명 : 기존값}, 수정값) 차원 확인(shape) 변수명.shape 분리한 데이터셋의 차원을 볼 수 있음 차원이란 '데이터셋에 포함된 값의 개수', '독립변수의 개수'를 의미함 다시말해 행과 열의 개수를 알려준다. shape는 속성이기때문에 ()를 붙여주면 안 된다. enumerate enumerate 함수는 리스트의 원소에 인덱스를 부여하는 기능을 가지고있다. 예를들어 df = ['food', 'animal', 'date', 'people'] 라는 리스트가 ..
SQL 2024.02.02 - [데이터 분석 공부/SQL] - SQL 예제 풀이(Leetcode - Confirmation Rate) SQL 예제 풀이(Leetcode - Confirmation Rate) https://leetcode.com/problems/confirmation-rate/description/ LeetCode - The World's Leading Online Programming Learning Platform Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your n eyeoftheworld1209.tistory...
 머신러닝 - 전처리(인코딩, 스케일링)에서부터 로지스틱 회귀를 적용한 예측 모델 생성까지(feat. 선형회귀와 로지스틱 회귀의 차이, 스케일링의 정규화와 표준화는 각각 언제 사용하는지)(24.02..
머신러닝 - 전처리(인코딩, 스케일링)에서부터 로지스틱 회귀를 적용한 예측 모델 생성까지(feat. 선형회귀와 로지스틱 회귀의 차이, 스케일링의 정규화와 표준화는 각각 언제 사용하는지)(24.02..
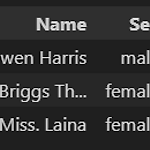
Step 데이터 불러와서 살펴보기 Sibsp(자녀수) + Parch(부모수) 이상치(Outlier) 처리 결측치 처리 인코딩(수치형 데이터) 스케일링(범주형 데이터) 로지스틱회귀(Logistic Regression) / 모델 평가 test 데이터에 적용 1. 데이터 불러와서 살펴보기 train_df = pd.read_csv('경로/train.csv') test_df = pd.read_csv('경로/test.csv') train_df.head(3) train_df.info() train_df.describe(include='all') 다양한 컬럼들이 존재하는데 이 중 'Age', 'Fare', 'Family', 'Embarked', 'Pcalss', 'Sex'를 독립변수로 'Survived'를 종속변수로 ..